前端大师课
事件循环
浏览器的进程模型
何为进程?
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配的基本单位,是操作系统结构的基础。
程序运行需要有它自己专属的内存空间,可以把这块内存空间简单的理解为进程
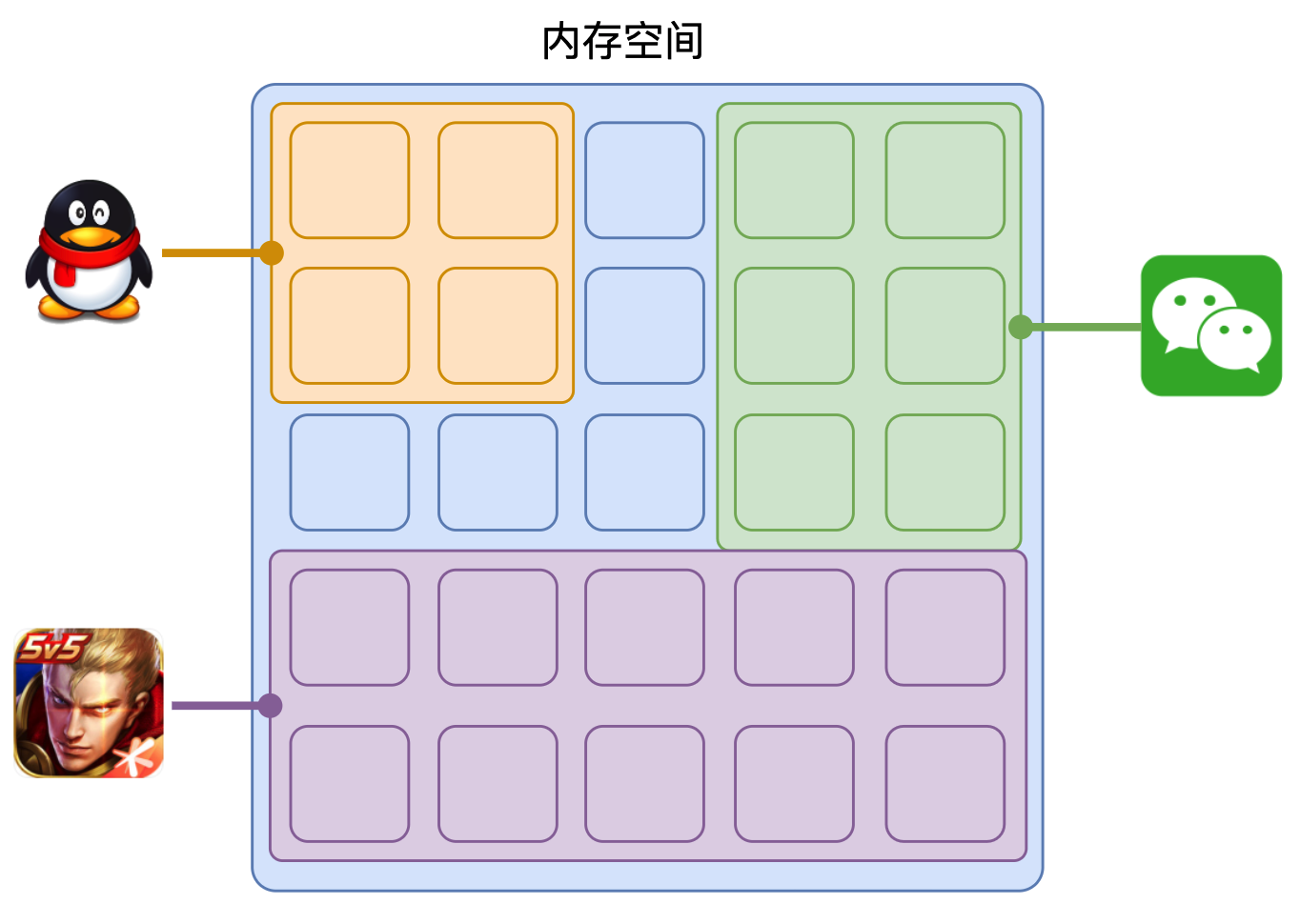
每个应用至少有一个进程,进程之间相互独立,即使要通信,也需要双方同意。
何为线程?
有了进程后,就可以运行程序的代码了。
运行代码的「人」称之为「线程」。
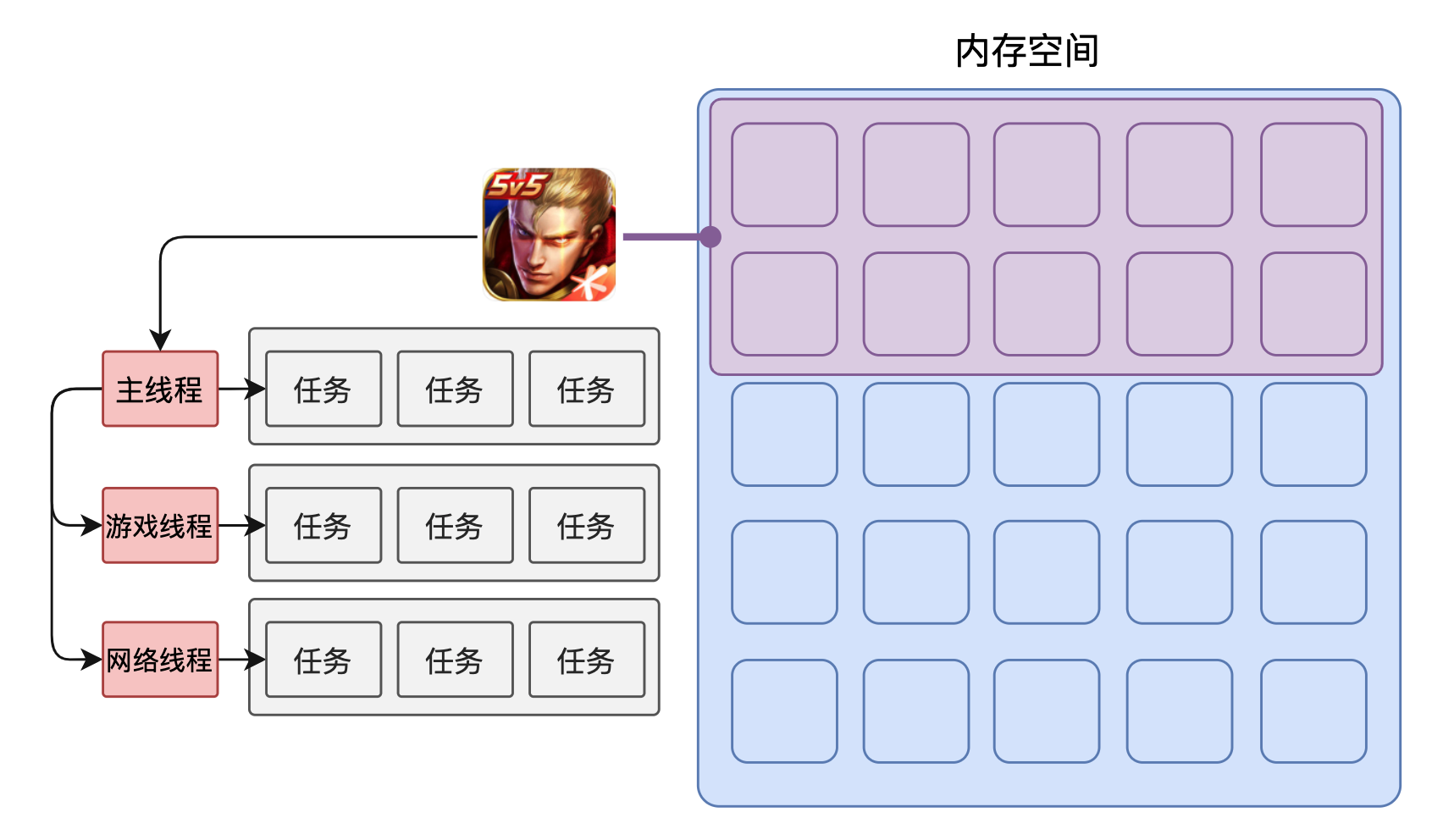
一个进程至少有一个线程,所以在进程开启后会自动创建一个线程来运行代码,该线程称之为主线程。
如果程序需要同时执行多块代码,主线程就会启动更多的线程来执行代码,所以一个进程中可以包含多个线程。
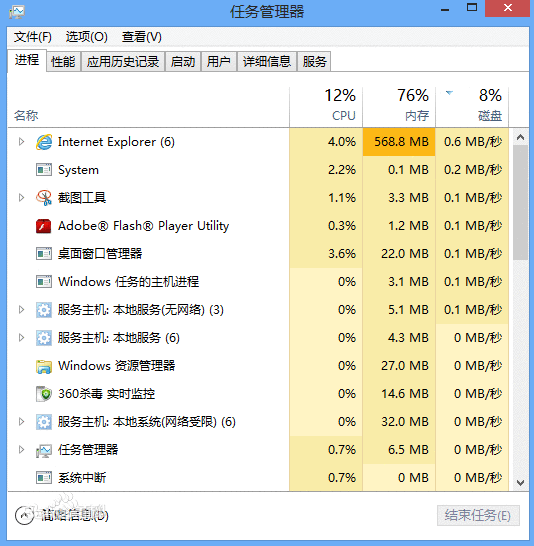
浏览器有哪些进程和线程?
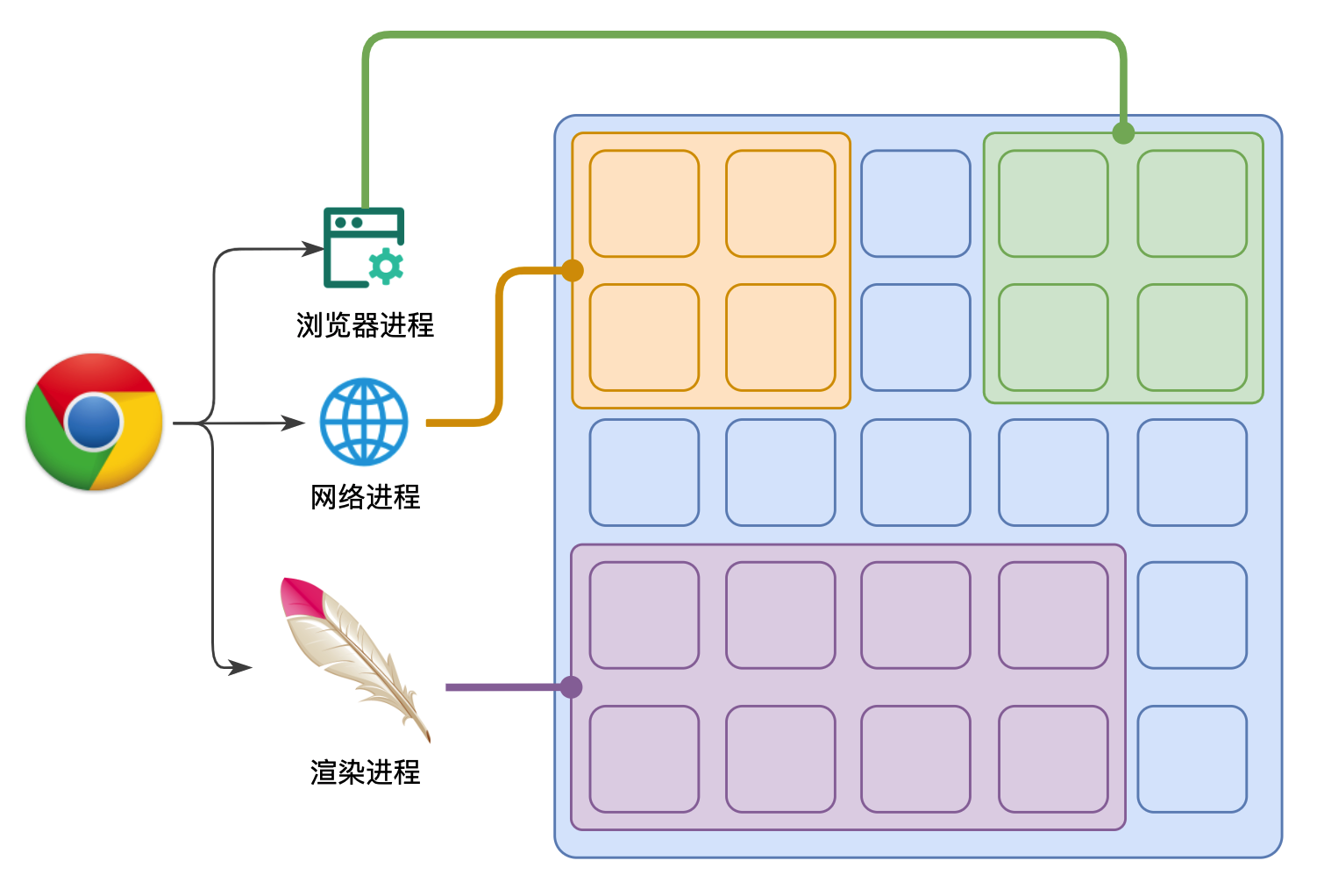
浏览器是一个多进程多线程的应用程序
浏览器内部工作极其复杂。
为了避免相互影响,为了减少连环崩溃的几率,当启动浏览器后,它会自动启动多个进程。
可以在浏览器的任务管理器中查看当前的所有进程
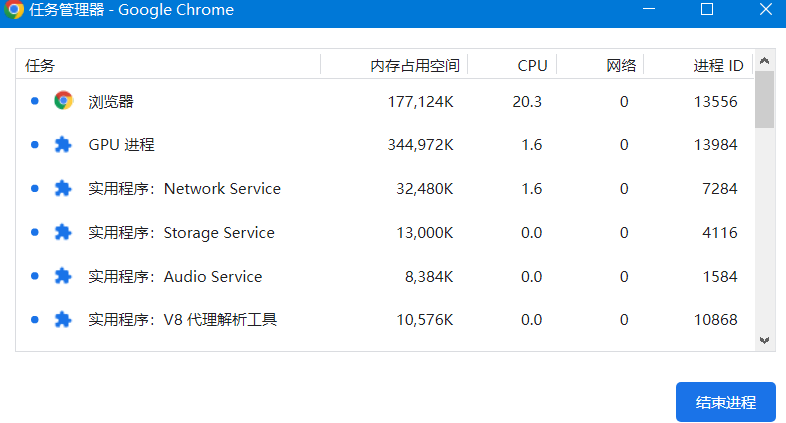
其中,最主要的进程有:
浏览器进程
主要负责界面显示、用户交互、子进程管理等。浏览器进程内部会启动多个线程处理不同的任务
网络进程
负责加载网络资源。网络进程内部会启动多个线程来处理不同的网络任务。
渲染进程。主要任务是将HTML、CSS和JavaScript转换为用户可以与之交互的网页。
渲染进程启动后,会开启一个渲染主线程,主线程负责执行 HTML、CSS、JS 代码。
默认情况下,浏览器会为每个标签页开启一个新的渲染进程,以保证不同的标签页之间不相互影响。
插件进程。主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响。
GPU进程。主要负责3D CSS的渲染等功能。
每个站点一个进程
渲染主线程是如何工作的?
渲染主线程是浏览器中最繁忙的线程,需要它处理的任务包括但不限于:
- 解析 HTML
- 解析 CSS
- 计算样式
- 布局
- 处理图层
- 每秒把页面画 60 次
- 执行全局 JS 代码
- 执行事件处理函数
- 执行计时器的回调函数
- ……
思考题:为什么渲染进程不适用多个线程来处理这些事情?
浏览器渲染和JS执行共用一个线程,且必须是单线程操作,多线程会产生渲染DOM冲突。
在构建DOM时,HTML解析器若遇到JavaScript代码,会暂停构建DOM,将控制权移交给JavaScript引擎,等JavaScript引擎运行完毕,浏览器再从中断的地方恢复DOM构建。
要处理这么多的任务,主线程遇到了一个前所未有的难题:如何调度任务?
比如:
- 我正在执行一个 JS 函数,执行到一半的时候用户点击了按钮,我该立即去执行点击事件的处理函数吗?
- 我正在执行一个 JS 函数,执行到一半的时候某个计时器到达了时间,我该立即去执行它的回调吗?
- 浏览器进程通知我“用户点击了按钮”,与此同时,某个计时器也到达了时间,我应该处理哪一个呢?
- ……
渲染主线程想出了一个绝妙的主意来处理这个问题:排队
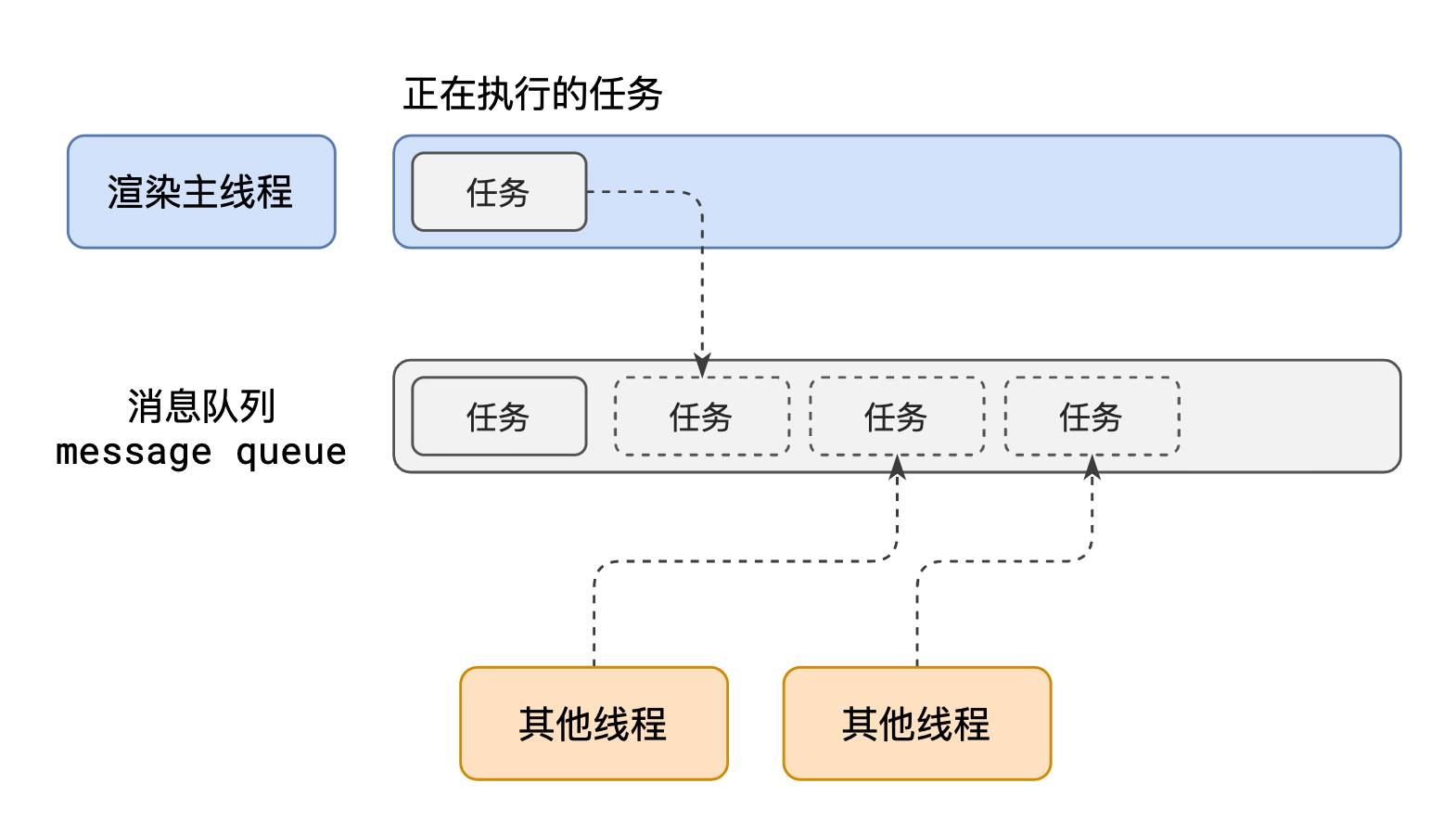
- 在最开始的时候,渲染主线程会进入一个无限循环
- 每一次循环会检查消息队列中是否有任务存在。如果有,就取出第一个任务执行,执行完一个后进入下一次循环;如果没有,则进入休眠状态。
- 其他所有线程(包括其他进程的线程)可以随时向消息队列添加任务。新任务会加到消息队列的末尾。在添加新任务时,如果主线程是休眠状态,则会将其唤醒以继续循环拿取任务
这样一来,就可以让每个任务有条不紊的、持续的进行下去了。
整个过程,被称之为事件循环(消息循环)
何为异步?
代码在执行过程中,会遇到一些无法立即处理的任务,比如:
- 计时完成后需要执行的任务 ——
setTimeout、setInterval - 网络通信完成后需要执行的任务 –
XHR、Fetch - 用户操作后需要执行的任务 –
addEventListener
如果让渲染主线程等待这些任务的时机达到,就会导致主线程长期处于「阻塞」的状态,从而导致浏览器「卡死」
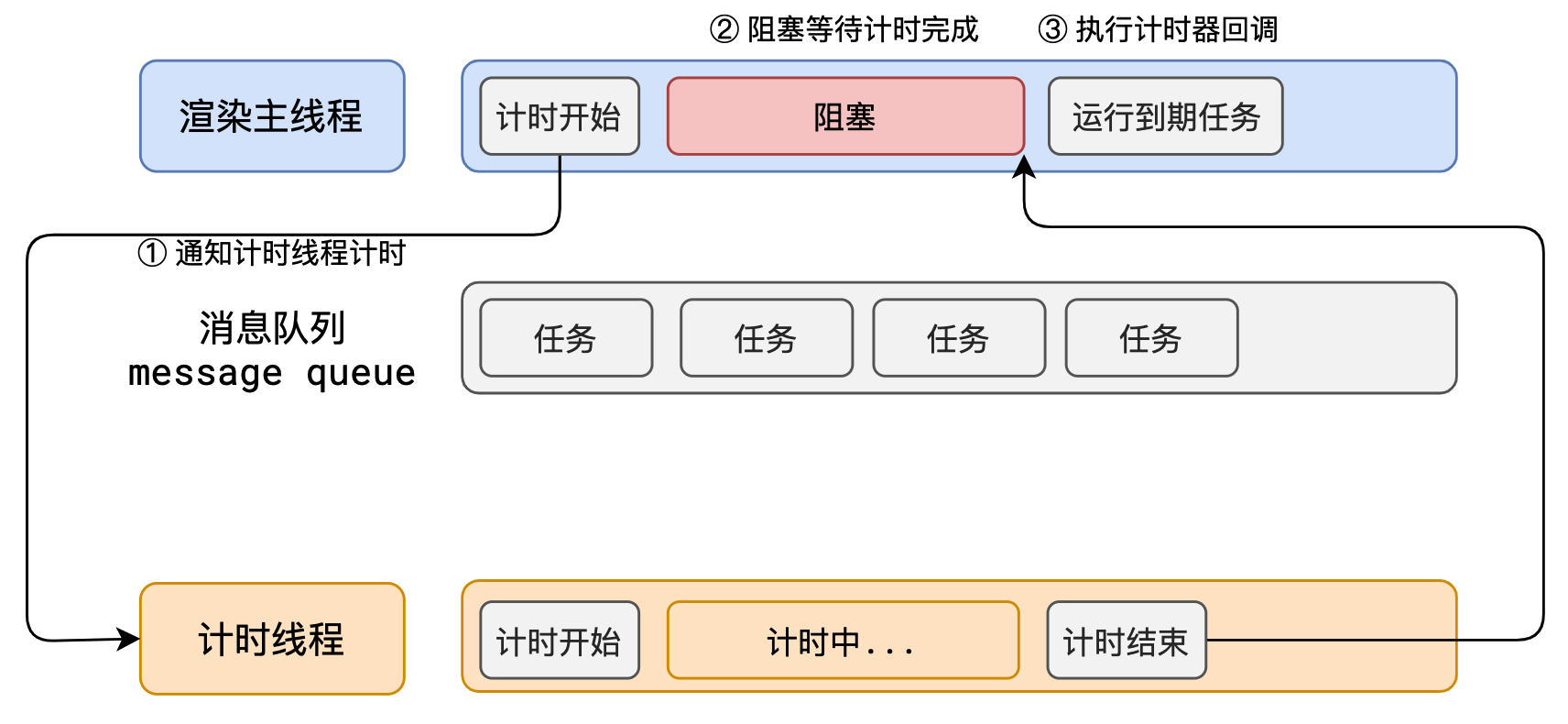
渲染主线程承担着极其重要的工作,无论如何都不能阻塞!
因此,浏览器选择异步来解决这个问题
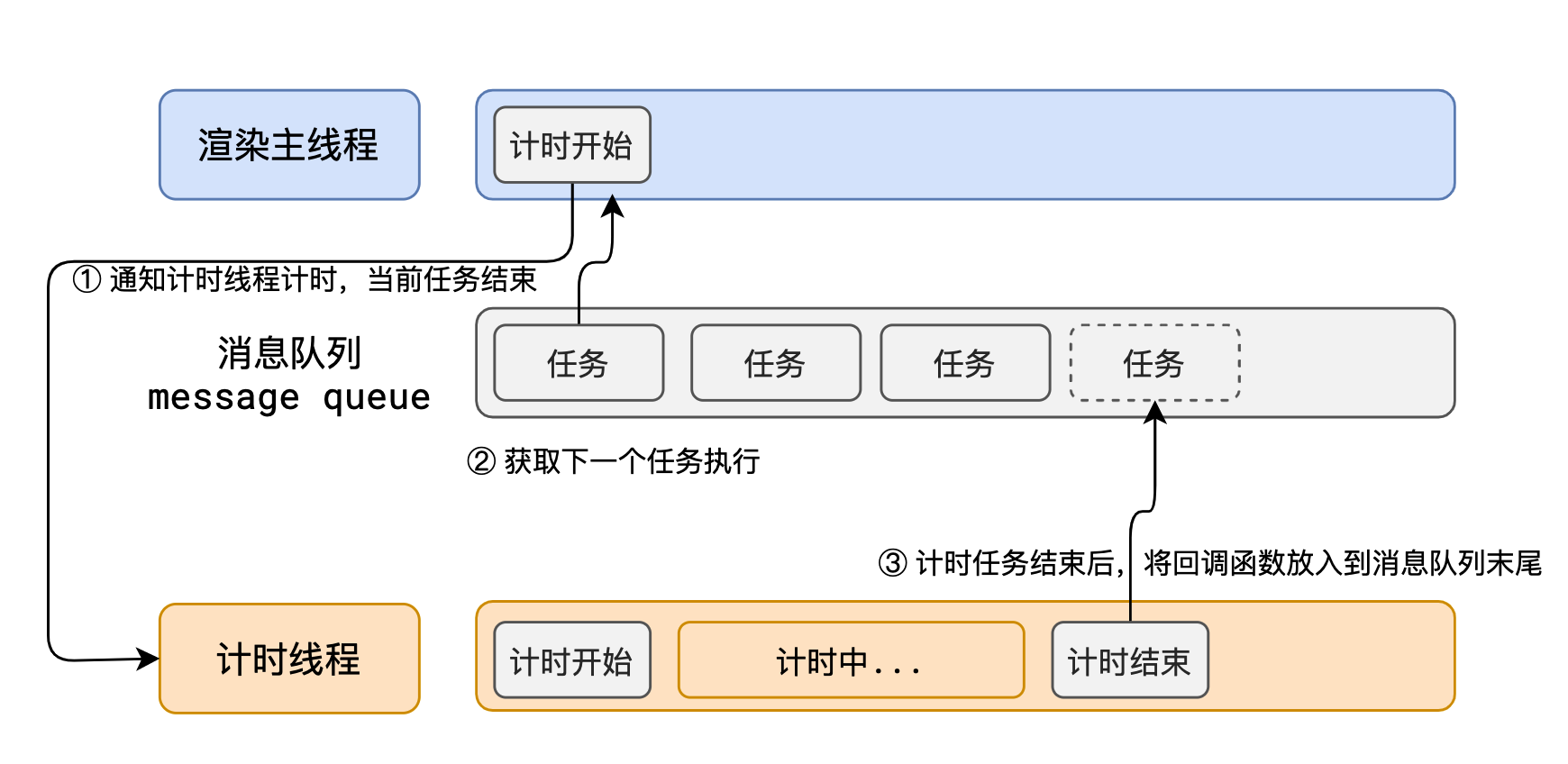
使用异步的方式,渲染主线程永不阻塞
面试题:如何理解 JS 的异步?
参考答案:
JS是一门单线程的语言,这是因为它运行在浏览器的渲染主线程中,而渲染主线程只有一个。
而渲染主线程承担着诸多的工作,渲染页面、执行 JS 都在其中运行。
如果使用同步的方式,就极有可能导致主线程产生阻塞,从而导致消息队列中的很多其他任务无法得到执行。这样一来,一方面会导致繁忙的主线程白白的消耗时间,另一方面导致页面无法及时更新,给用户造成卡死现象。
所以浏览器采用异步的方式来避免。具体做法是当某些任务发生时,比如计时器、网络、事件监听,主线程将任务交给其他线程去处理,自身立即结束任务的执行,转而执行后续代码。当其他线程完成时,将事先传递的回调函数包装成任务,加入到消息队列的末尾排队,等待主线程调度执行。
在这种异步模式下,浏览器永不阻塞,从而最大限度的保证了单线程的流畅运行。
JS为何会阻碍渲染?
1 | |
3秒后内容才会被改变

任务有优先级吗?
任务没有优先级,在消息队列中先进先出
但消息队列是有优先级的
根据 W3C 的最新解释:
- 每个任务都有一个任务类型,同一个类型的任务必须在一个队列,不同类型的任务可以分属于不同的队列(一个队列可以有多个类型的任务)。
在一次事件循环中,浏览器可以根据实际情况从不同的队列中取出任务执行。 - 浏览器必须准备好一个微队列,微队列中的任务优先所有其他任务执行
https://html.spec.whatwg.org/multipage/webappapis.html#perform-a-microtask-checkpoint
随着浏览器的复杂度急剧提升,W3C 不再使用宏队列的说法
在目前 chrome 的实现中,至少包含了下面的队列:
- 延时队列:用于存放计时器到达后的回调任务,优先级「中」
- 交互队列:用于存放用户操作后产生的事件处理任务,优先级「高」
- 微队列:用户存放需要最快执行的任务,优先级「最高」
微队列是JavaScript中的一种数据结构,用来保存待执行的微任务(回调),例如promise的回调、MutationObserver的回调以及I/O操作、UI渲染等。
微队列和宏队列是异步队列,宏队列用来保存待执行的宏任务(回调),例如定时器回调、DOM事件回调、ajax回调等。当一个宏队列执行完毕,立即执行最近添加的微队列。
添加任务到微队列的主要方式主要是使用 Promise、MutationObserver
例如:
2// 立即把一个函数添加到微队列
Promise.resolve().then(函数)
1 | |
1 | |
1 | |
1 | |
先点击开始再点击添加交互任务
说明点击事件(交互队列)优先级高于延时队列的任务

阐述一下 JS 的事件循环
事件循环又叫做消息循环,是浏览器渲染主线程的工作方式。
在 Chrome 的源码中,它开启一个不会结束的 for 循环,每次循环从消息队列中取出第一个任务执行,而其他线程只需要在合适的时候将任务加入到队列末尾即可。
过去把消息队列简单分为宏队列和微队列,这种说法目前已无法满足复杂的浏览器环境,取而代之的是一种更加灵活多变的处理方式。
根据 W3C 官方的解释,每个任务有不同的类型,同类型的任务必须在同一个队列,不同的任务可以属于不同的队列。不同任务队列有不同的优先级,在一次事件循环中,由浏览器自行决定取哪一个队列的任务。但浏览器必须有一个微队列,微队列的任务一定具有最高的优先级,必须优先调度执行。
JS 中的计时器能做到精确计时吗?为什么?
不行,因为:
- 计算机硬件没有原子钟,无法做到精确计时
- 操作系统的计时函数本身就有少量偏差,由于 JS 的计时器最终调用的是操作系统的函数,也就携带了这些偏差
- 按照 W3C 的标准,浏览器实现计时器时,如果嵌套层级超过 5 层,则会带有 4 毫秒的最少时间,这样在计时时间少于 4 毫秒时又带来了偏差
- 受事件循环的影响,计时器的回调函数只能在主线程空闲时运行,因此又带来了偏差
浏览器延迟的解释
- JavaScript是单线程的:在浏览器中,JavaScript 是单线程运行的,这意味着它一次只能执行一个任务。这个线程被称为主线程。
- 计时器是异步的:
setTimeout和setInterval等计时器函数允许你在将来的某个时间点或间隔后执行代码,它们是异步的,不会阻塞主线程的执行。- 任务队列:浏览器使用任务队列(task queue)来管理异步任务。当计时器时间到达时,相关的回调函数将被添加到任务队列中等待执行。
- 最小延迟:为了避免过于频繁的任务排队和执行,浏览器通常会设置一个最小的定时器延迟。在大多数浏览器中,这个最小延迟是4毫秒。这意味着如果你设置一个1毫秒的定时器,它实际上会在4毫秒后执行,而不是1毫秒后。
- 嵌套计时器:如果你在一个计时器回调内部再次设置一个计时器,这就被称为嵌套计时器。嵌套计时器会导致多个计时器回调函数按顺序排队执行。
- 超过5层的限制:有些浏览器实现有一个限制,当嵌套计时器的层级超过一定数量(通常是5层),它们会将嵌套的计时器合并成一个,以减少性能开销。这意味着如果你设置一个嵌套层级超过5层的计时器,最小延迟将会叠加,通常是4毫秒的倍数。这是为了避免潜在的性能问题和无限递归。
这个现象是浏览器引擎的具体实现细节,不同浏览器可能会有不同的行为,但大多数浏览器都会采用类似的策略来管理计时器。因此,在编写依赖于计时器的代码时,需要注意最小延迟和嵌套计时器可能会导致的延迟问题,以确保你的应用行为符合预期。
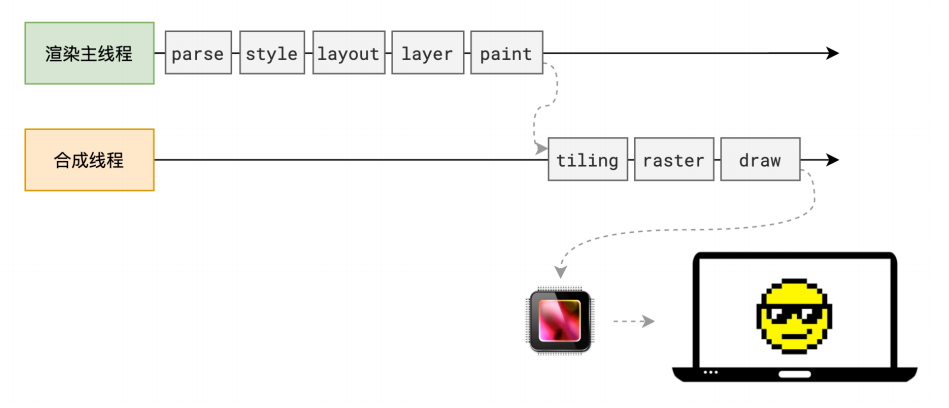
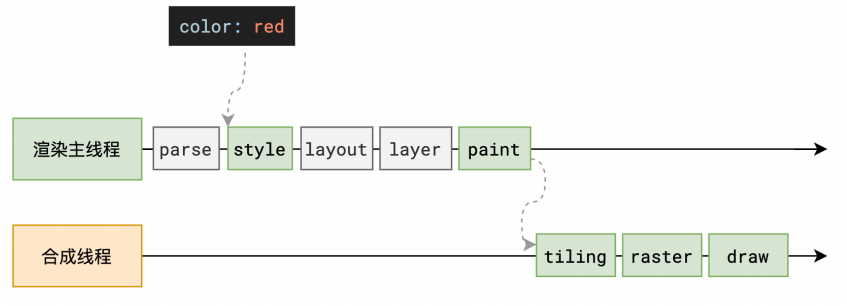
浏览器渲染原理
参考文章:
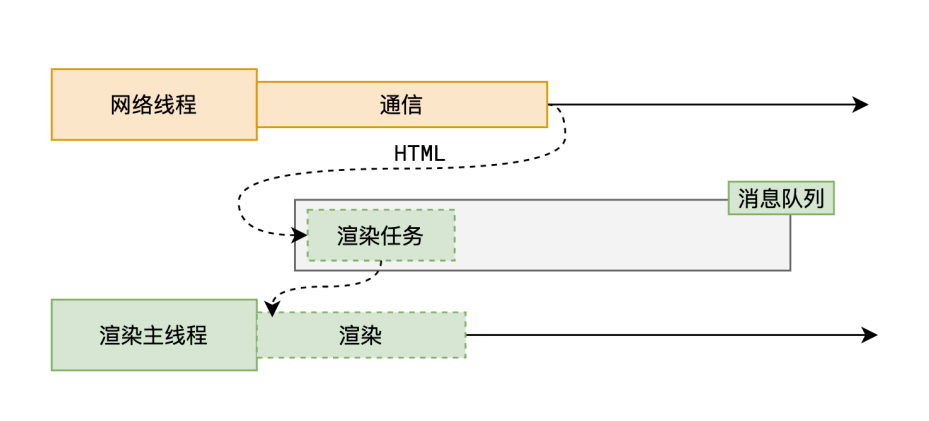
渲染流程
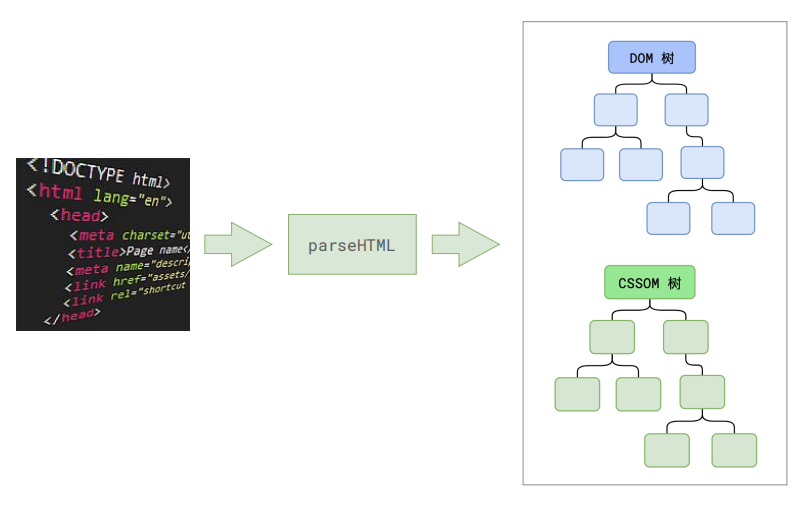
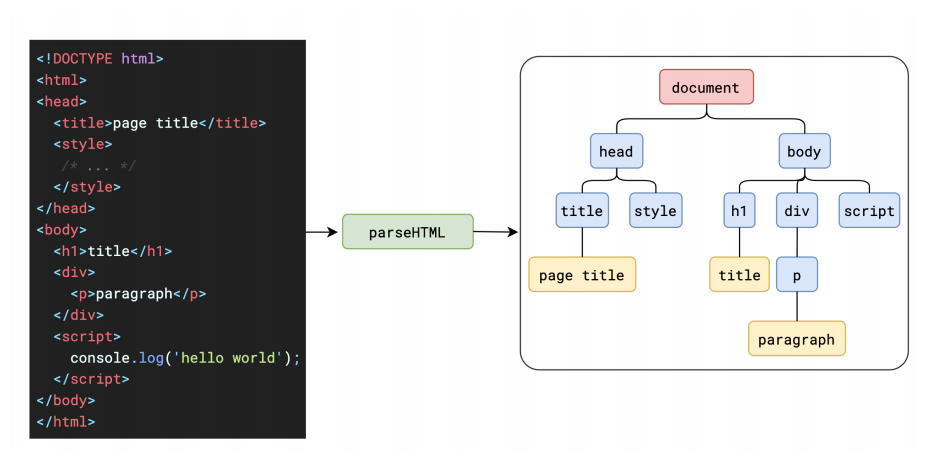
渲染流程图
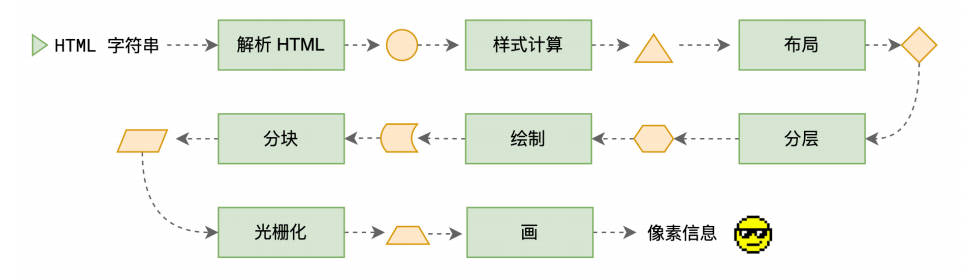
解析 HTML - Parse HTML
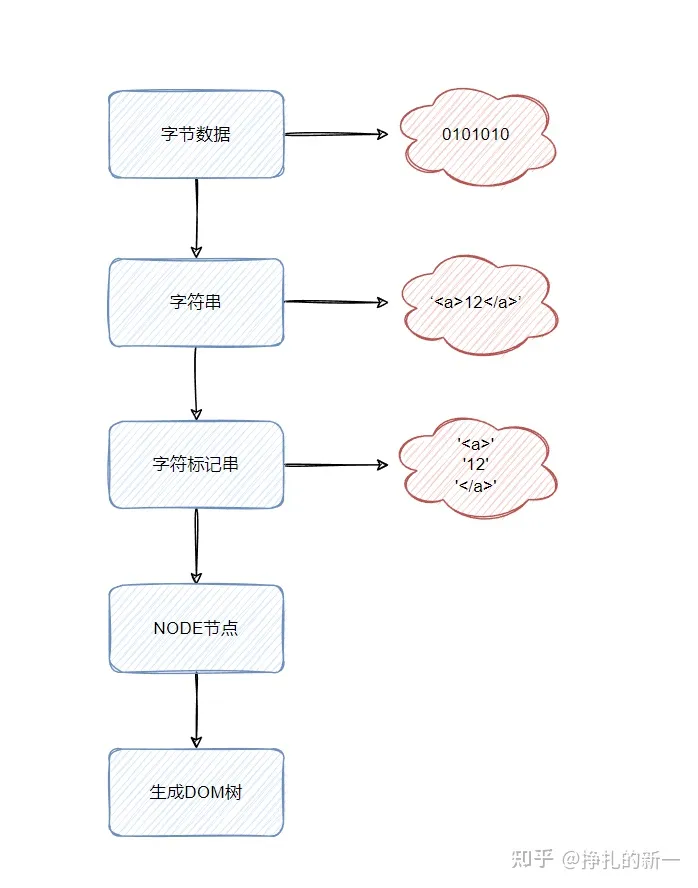
解析我们的HTML,生成DOM树结构 首先会拿到html的整体的字符串,进行标记化(token)
为什么要标记化,因为浏览器是不能识别这些字符串需要进行标记化的处理,本质上就是把这段字符串的html进行标签类型的拆分,因为是一长串的字符串需要对字符串进行解析成node节点,所以会进行标记化,方便浏览器根据标记的标签去进行DOM树渲染

html字符串->tokens流

tokens流->DOM树
HTML 解析过程中遇到 CSS 代码怎么办?
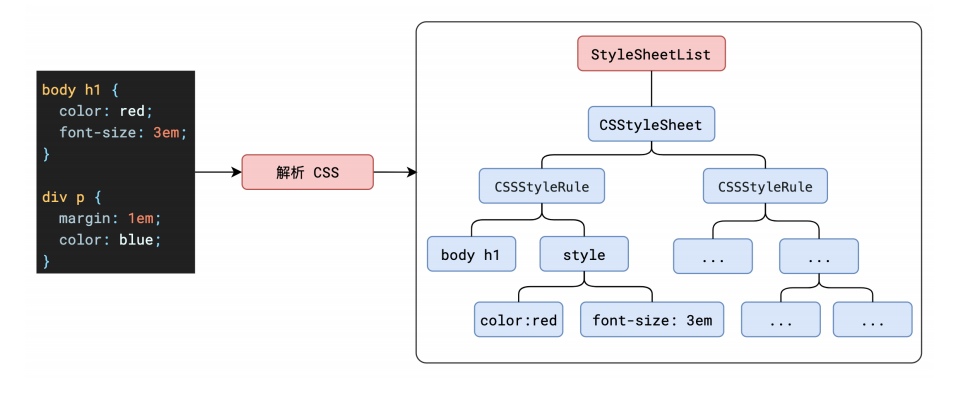
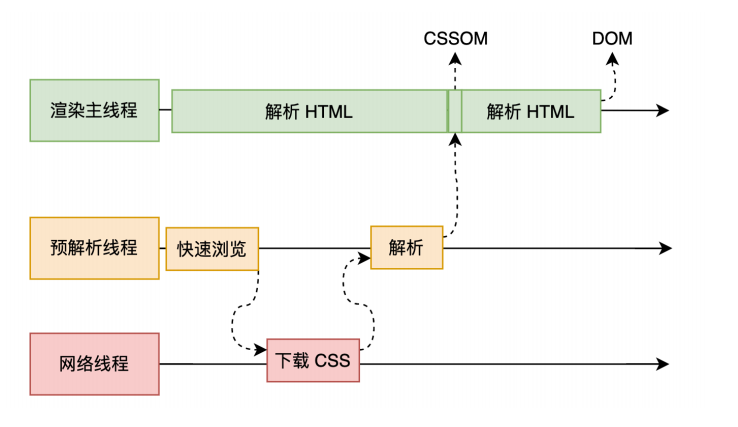
为了提⾼解析效率,浏览器会启动⼀个预解析器率先下载和解析 CSS
但是我们在解析HTML的过程当中我们也会碰到style和link这样的标签,这些样式和交互的内容就涉及到CSS的解析 浏览器在解析的时候为了提高效率会启动一个预解析线程,这个线程主要做的就是扫描出外部的style和js文件进行异步下载解析,解析完成后如果渲染主线程没有没有完成会直接把解析的结果CSSOM添加到主线程中 style和link标签的解析和下载都是在预线程当中进行的,所以css下载不了的情况下也不会影响主线程的进度。最后css 标记化(token)也会形成一颗CSSOM树
HTML 解析过程中遇到 JS 代码怎么办?
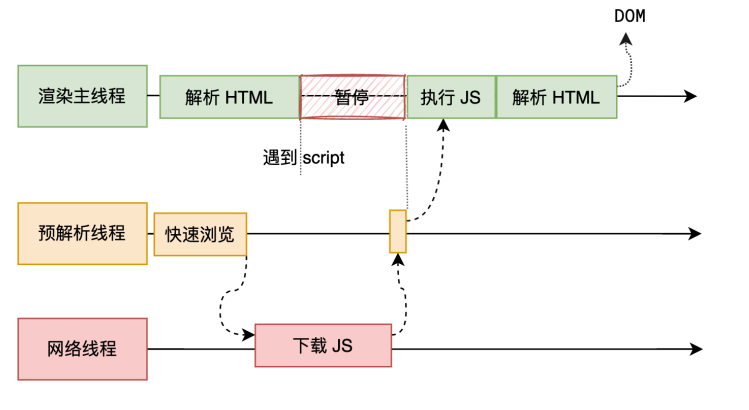
渲染主线程遇到 JS 时必须暂停⼀切⾏为,等待下载执⾏完后才能继续预解析线程可以分担⼀点下载 JS 的任务
因为主线程解析到script标签的时候,会停止解析HTML,并且会等待js文件下载好,然后解析完毕之后才继续进行解析,因为js代码是可以修改当前的DOM树的形成的,所以代码必须要等JS文件解析完毕之后才能继续生成DOM树
如果主线程解析到script位置,会停止解析 HTML,转而等待 JS 文件下载好,并将全局代码解析执行完成后,才能继续解析 HTML。这是因为 JS 代码的执行过程可能会修改当前的 DOM 树,所以 DOM 树的生成必须暂停。这就是 JS 会阻塞 HTML 解析的根本原因。
通常script的标签都是在body标签的底部,这样就不会因为碰到较大的js文件下载而影响我们的首屏渲染 在最近几年的版本的浏览器中也提供了以下方式避免了js代码阻塞渲染的情况
- async
- defer
- prefetch
- preload
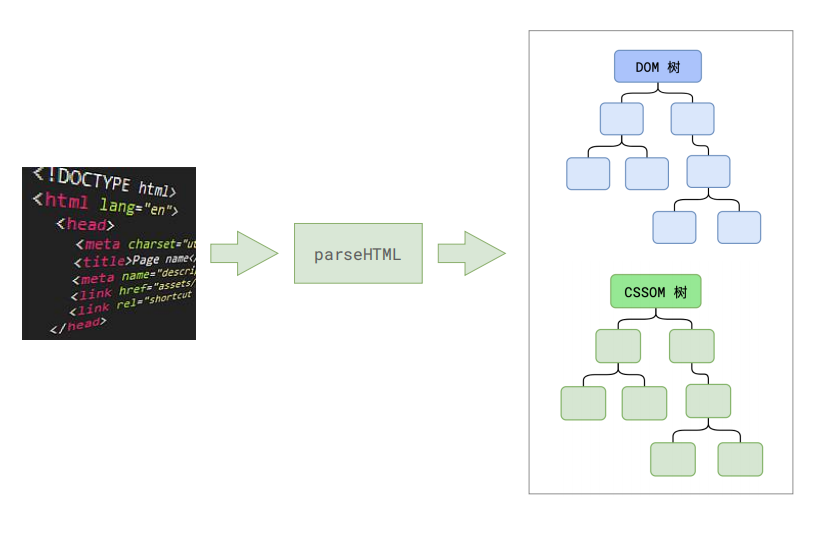
第一步完成后,会得到 DOM 树和 CSSOM 树,浏览器的默认样式、内部样式、外部样式、行内样式均会包含在 CSSOM 树中。
DOM解析和CSS解析会相互阻塞吗?
CSSOM 树和 DOM 树是独立的两个数据结构,它们并没有一一对应关系,浏览器在构建 DOM 树的同时,如果样式也加载完成了,那么 CSSOM 树也会同步构建。
在浏览器的渲染过程中,DOM 解析和 CSS 解析通常不会相互阻塞,它们可以并行进行。这是因为 DOM(文档对象模型)和 CSS(层叠样式表)是两个独立的步骤,它们可以同时开始解析,不必等待对方完成。
具体来说,浏览器在接收到HTML和CSS文件后,会同时进行以下两个主要步骤:
- DOM 解析: 浏览器开始解析HTML文档并构建DOM树,表示文档的结构和内容。DOM解析通常是逐行进行的,遇到一个HTML标签就会构建相应的DOM节点,这个过程在解析整个文档的同时进行。
- CSS 解析: 浏览器同时开始解析CSS文件,构建样式规则树(Style Rule Tree),并将元素与样式规则进行匹配,以确定每个元素的计算样式。CSS解析也可以并行进行,而不必等待DOM解析完成。
然而,尽管DOM解析和CSS解析可以并行进行,但在某些情况下,它们的结果可能会相互影响,例如:
- 如果在HTML中有内联的样式(
<style>标签或style属性),则浏览器需要等到相关的CSS解析完成才能继续解析DOM,以确保内联样式的应用是准确的。 - 如果JavaScript代码依赖于特定DOM元素的样式计算结果,那么当浏览器执行JavaScript时,可能需要等待CSS解析和样式计算完成,以确保脚本在正确的样式上运行。
总的来说,DOM解析和CSS解析通常是并行进行的,但在特定情况下可能会相互影响,需要浏览器在内部进行协调,以确保页面的正确渲染。3
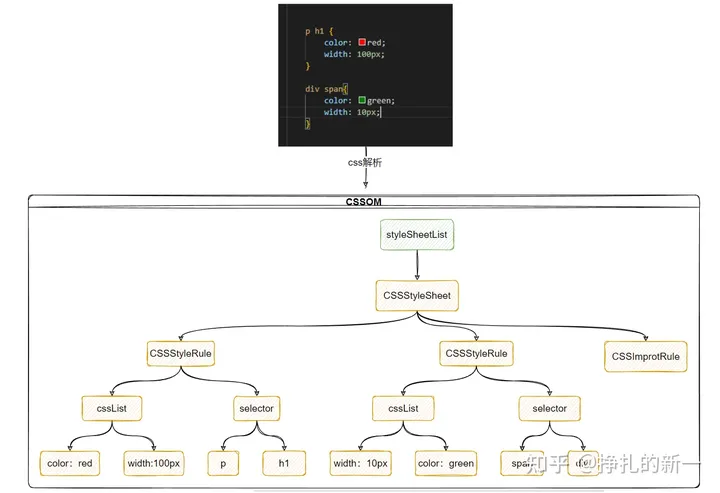
CSSOM数据结构如何?
1 | |


样式计算 - Recalculate Style

接下来把解析出来的DOMTree和CSSOMTree结合到一起 主线程会遍历DOM树的每个节点最终计算出每个节点的样式,称之位Computed Style 在这个计算的过程中,我们的预设值会变成绝对值,比如我们的color:red会变成 color:rgb(255,0,0),相对单位会变成绝对单位,比如em会变成px
样式标准化

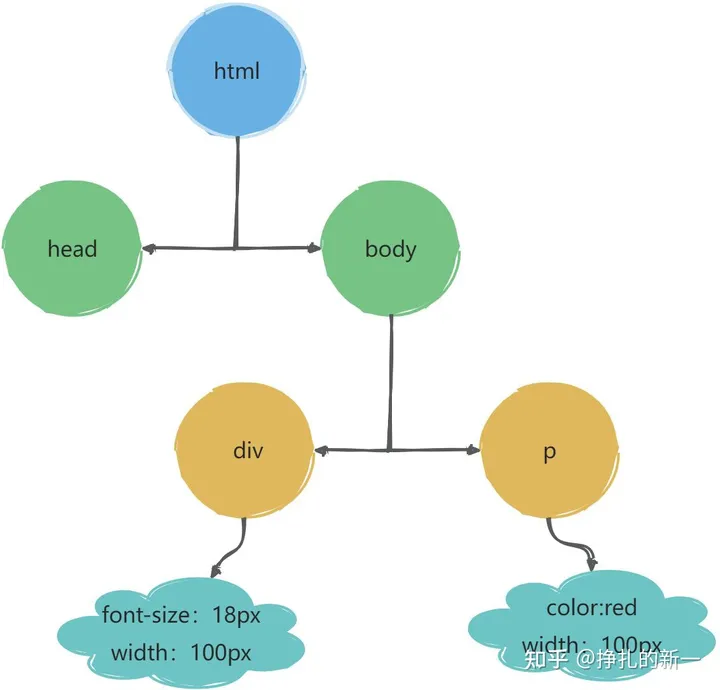
浏览器确定每个节点的样式之后,会形成样式规则树,这颗树上记录了每一个DOM节点的样式 另外计算属性会对每一个节点进行所有样式的属性值赋值,如果某个节点开发时没有赋予样式,将使用样式的默认值或者继承植 经过样式计算后会把DOM树和CSSOM树结合成带有样式的DOM树如下图
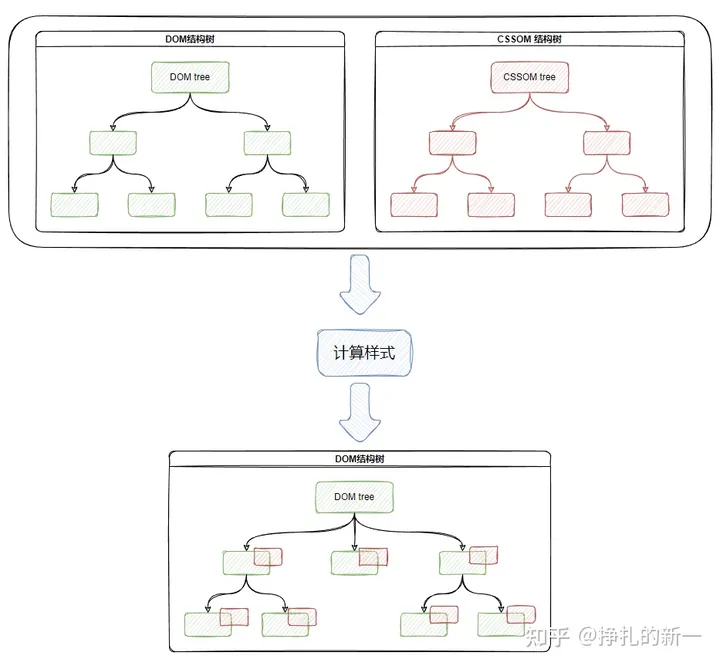
合成的这个Dom树就是渲染树
为什么要构建渲染树?
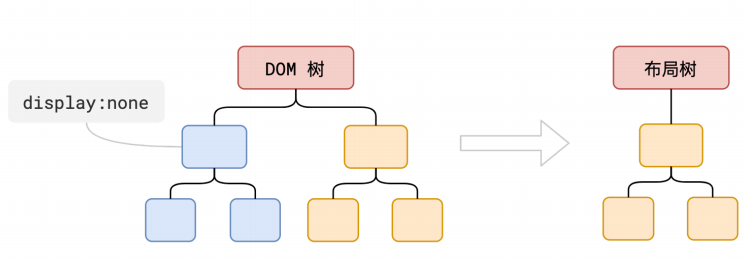
DOM树可能包含一些不可见的元素,比如head标签,使用display:none;属性的元素等。所以在显示页面之前,还要额外地构建一棵只包含可见元素的渲染树。
styleMap和computedStyleMap
styleMap 和 computedStyleMap 是与 CSS 样式处理相关的 JavaScript API,它们用于在浏览器环境中操作和查询元素的样式信息。这两个 API 提供了更直观和类型安全的方法来处理样式,而不必直接操作元素的 style 属性或使用字符串来表示样式。
styleMap:styleMap是一种用于处理和操作元素内联样式(style属性)的 API。它允许你使用更直观的方式来获取、设置和修改元素的样式属性,而无需手动操作字符串。styleMap对象的属性和方法与 CSS 属性和值之间存在一一对应的关系,使样式的处理更容易理解和维护。例如,要设置一个元素的背景颜色,可以使用
styleMap如下所示:1
2javascriptCopy codeconst element = document.getElementById('myElement');
element.attributeStyleMap.set('background-color', 'red');computedStyleMap:computedStyleMap允许你查询计算样式,即元素应用的最终样式信息,包括从外部样式表和内联样式中计算得出的样式。它提供了一种直接访问和操作计算样式属性的方法。例如,要获取元素的计算背景颜色,可以使用
computedStyleMap如下所示:1
2
3javascriptCopy codeconst element = document.getElementById('myElement');
const computedStyle = getComputedStyle(element);
const backgroundColor = computedStyleMap.get('background-color');computedStyleMap还提供了方法来查询和操作其他计算样式属性,使你可以轻松地获取和操作元素的最终呈现样式。
总的来说,styleMap 和 computedStyleMap 提供了更现代和便捷的方式来处理元素的样式,使开发人员能够以更直观和类型安全的方式操作CSS样式,而无需深入处理字符串或直接操作 style 属性。这些 API 在构建交互性强、动态样式变化的 Web 应用中特别有用。请注意,它们可能需要较新版本的浏览器来支持。

attributeStyleMap和computedStyleMap都是用来存放样式的对象,但两者有一些区别。 attributeStyleMap是一个对象,而computedStyleMap是一个函数。另外,computedStyleMap返回一个只读对象,只能执行get、has、entities、forEach等操作。 为什么要设计两个map?因为我们设置的样式不一定完全符合约定,attributeStyleMap是原始输入的样式,而computedStyleMap经过浏览器转换最后实际应用的样式。
1 | |
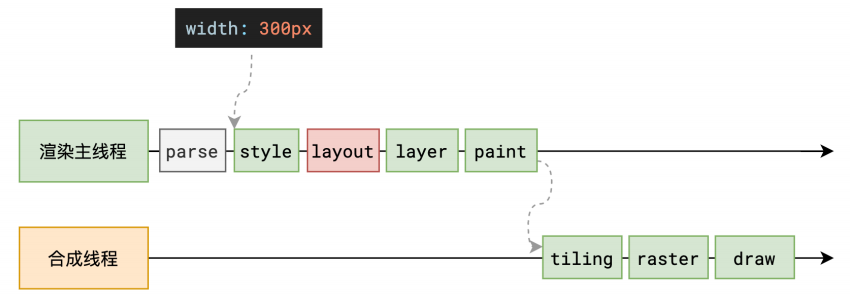
布局 - Layout
当浏览器解析HTML和样式计算后已经知道每个DOM节点所附带的样式了,但是还不足以呈现在页面上,因为我们还缺少每个元素在页面上的位置布局! 主线程这个时候会递归遍历完刚刚构建好的DOM树,由于DOM树上挂载了计算样式,就可以计算出布局树(layout tree),布局树上的每一个节点都挂载了它在页面上的位置也就是X,Y的坐标以及盒子模型的大小等几何信息
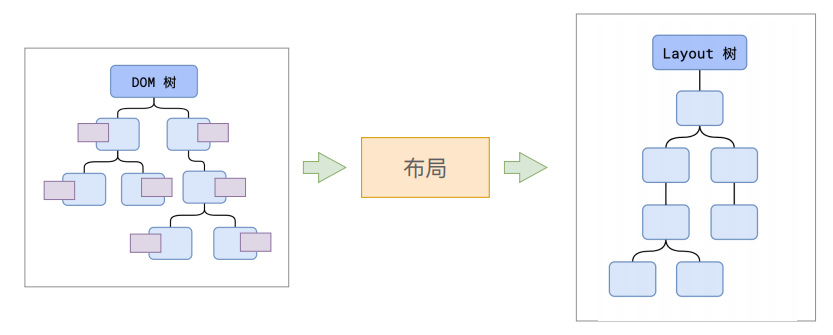
DOM 树 和 Layout 树不⼀定是⼀⼀对应的
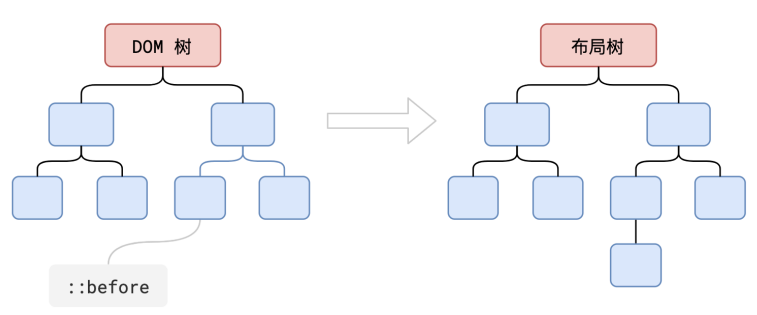
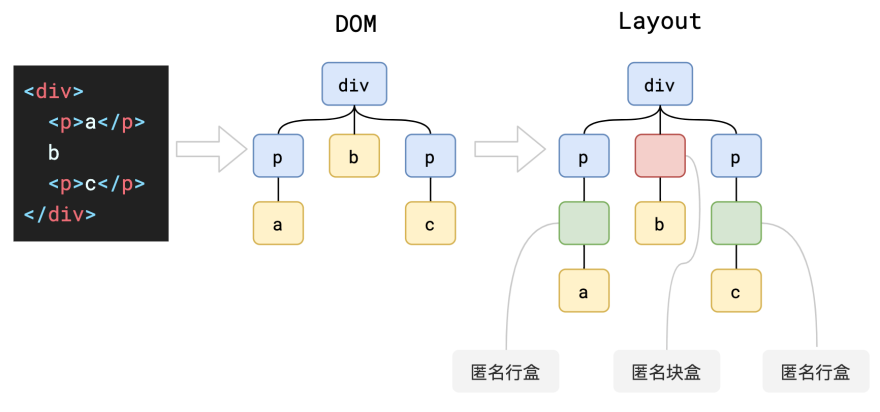
虽然生成了布局树,但是布局树的和之前的DOM树存在一些差异, 比如当有点节点挂载了display:none的样式时,就不会在布局树上展示 还有就是虽然伪类元素不会在DOM树上展示,但是如果伪类元素如果有几何信息它就会在布局树上展示 还有比较少有人知道的匿名行盒,匿名块盒等也会导致布局树和DOM树的结构差异化
分层 - Layer
当我们的布局树构建完成之后,接下来的一步就是分层! 为什么要分层呢?
分层的好处在于,改变某一层级的元素时,只会对该层级产生影响,从而提高效率
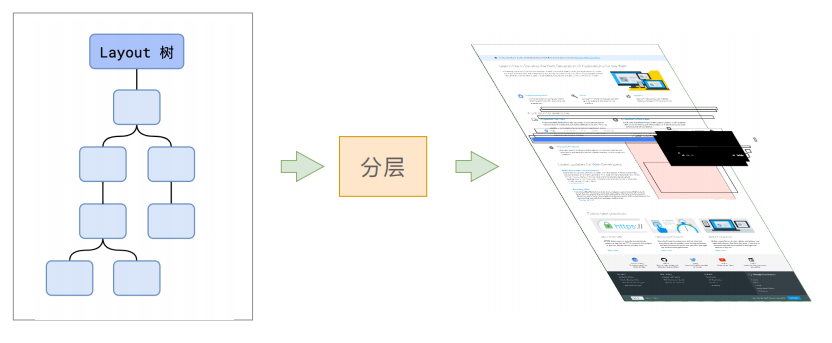
主线程会遍历整个布局树生成一个层次树(Layer Tree)确定元素需要放在那一层
堆叠上下文有关的属性都会影响分层
滚动条,堆叠上下文,transform,opacity等样式对少都会影响分层的结果,也可以通过z-index,will-change属性对其进行分层、
will-change 为web开发者提供了一种告知浏览器该元素会有哪些变化的方法,这样浏览器可以在元素属性真正发生变化之前提前做好对应的优化准备工作。 这种优化可以将一部分复杂的计算工作提前准备好,使页面的反应更为快速灵敏。
1 | |
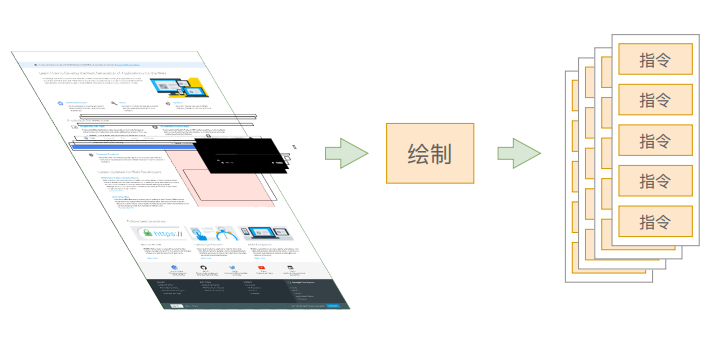
绘制 - Paint
这⾥的绘制,是为每⼀层⽣成如何绘制的指令
分层结束之后就开始绘制指令的生成了 主线程会给每一层单独生成一个绘制的指令集,用于生成该层的图像生成
渲染主线程的⼯作到此为⽌,剩余步骤交给其他线程完成
当主线程进行到这一步的时候你要注意了虽然生成了绘制的指令,但是还没有执行只是生成了指令,而且这个时候渲染主线程基本上已经完结了,接下来的工作将交给合成线程去完成
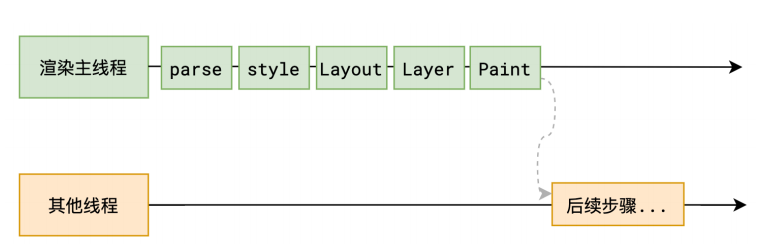
分块 - Tiling
分块会将每⼀层分为多个⼩的区域
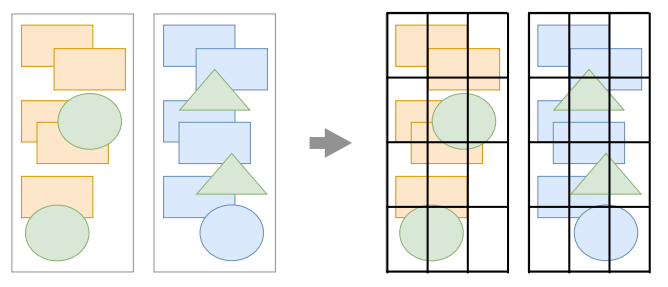
分块的⼯作是交给多个线程同时进⾏的
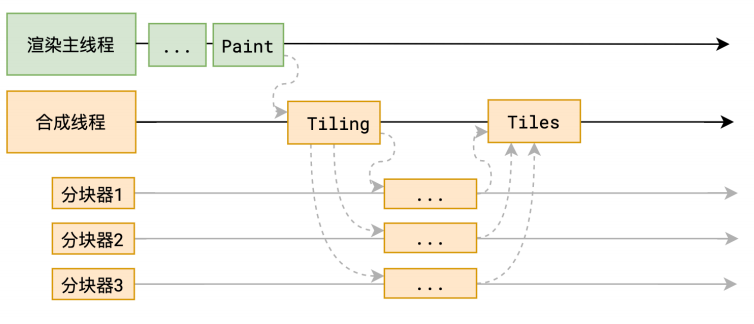
分块的目的: 提高网页展示的速度
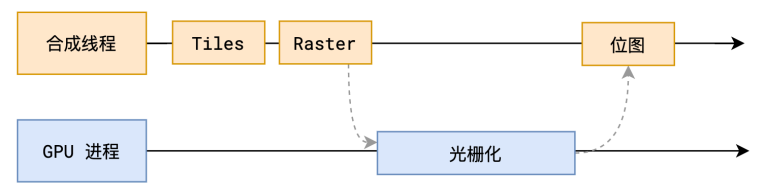
光栅化 - Raster
光栅化是将每个块变成位图
优先处理靠近视⼝的块
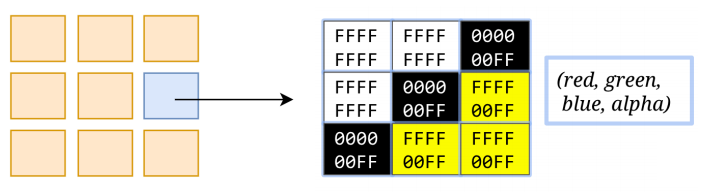
此过程会⽤到 GPU 加速
当我们的分块完成之后,接下来就光栅化的阶段了,更简单的说就是确认每一个像素点的rbg颜色信息 光栅化的操作不是由合成线程来做的,而是合成线程交给GPU进程,GPU进程会以极高的速度完成光栅化 GPU是专门干图形化处理的工作,他会开启多个线程进行绘制
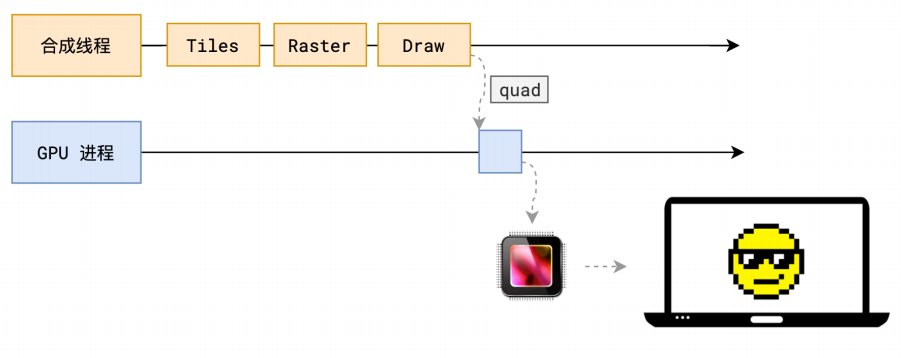
画 - Draw
最终我们才进行绘制,这是最后一步 所有的图形块被光栅化之后,合成线程就拿到了每个图层以及每个块的位置信息,从而生成了一个个的【指引】信息 指引会标识出每个图块应该渲染到屏幕的哪个位置,并且会考虑到旋转,缩放等变形效果 旋转,缩放等效果都发生在合成线程当中,和渲染主线程没有关系。所以为什么transform效率高就是这个原因
重排-reflow
reflow 的本质就是重新计算 layout 树。
当进行了会影响布局树的操作后,需要重新计算布局树,会引发 layout。
为了避免连续的多次操作导致布局树反复计算,浏览器会合并这些操作,当 JS 代码全部完成后再进行统一计算。所以,改动属性造成的 reflow 是异步完成的。
也同样因为如此,当 JS 获取布局属性时,就可能造成无法获取到最新的布局信息。
浏览器在反复权衡下,最终决定获取属性立即 reflow。
触发重排:当我们的渲染树发生元素的尺寸,结构或者属性发生变化的时候,浏览器会重新解析dom树和css树
当我们的操作引发了 DOM 树中几何尺寸的变化(改变元素的大小、位置、布局方式等),这时渲染树里有改动的节点和它影响的节点都要重新计算。这个过程就叫做重排,也称为回流。
下面这些操作会引起重排
- 页面首次渲染。
- 浏览器窗口大小发生变化
- 元素的内容发生变化
- 元素的尺寸或者位置发生变化
- 元素的字体大小发生变化
- 查询某些属性或者调用某些方法

重绘-repaint
repaint 的本质就是重新根据分层信息计算了绘制指令。
当改动了可见样式后,就需要重新计算,会引发 repaint。
由于元素的布局信息也属于可见样式,所以 reflow 一定会引起 repaint。
触发重绘:当页面中某些元素的样式发生变化,但不会影响其在文档流中的位置时,浏览器就会对元素进行重新绘制。
当对 DOM 的修改导致了样式的变化、但未影响其几何属性(比如修改颜色、背景色)时,浏览器不需重新计算元素的几何属性、直接为该元素绘制新的样式(会跳过重排环节),这个过程叫做重绘
color,visibility,opacity,background-color, box-shadow等。会引起重绘
总结:这也是为什么重排的触发比重绘更加影响性能的渲染,因为重排会触发渲染主的流程的重新渲染,而重绘只需要重新执行合成线程
为什么 transform 的效率高?
因为 transform 既不会影响布局也不会影响绘制指令,它影响的只是渲染流程的最后一个「draw」阶段
由于 draw 阶段在合成线程中,所以 transform 的变化几乎不会影响渲染主线程。反之,渲染主线程无论如何忙碌,也不会影响 transform 的变化。
演示
1 | |
点击死循环后,渲染主线程会卡住5秒钟,所以第二个会卡住,left偏移会引起重排,重排是在渲染主线程上执行的,所以会卡住。而transform只会引起重绘,是在合成线程上的,所以动画还会继续执行

CSS 属性计算过程
首先,不知道你有没有考虑过这样的一个问题,假设在 HTML 中有这么一段代码:
1 | |
上面的代码也非常简单,就是在 body 中有一个 h1 标题而已,该 h1 标题呈现出来的外观是如下:
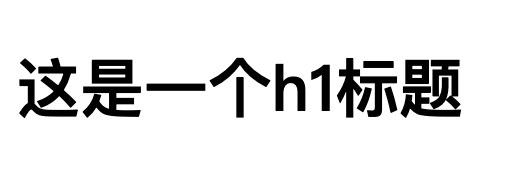
目前我们没有设置该 h1 的任何样式,但是却能看到该 h1 有一定的默认样式,例如有默认的字体大小、默认的颜色。
那么问题来了,我们这个 h1 元素上面除了有默认字体大小、默认颜色等属性以外,究竟还有哪些属性呢?
答案是该元素上面会有 CSS 所有的属性。你可以打开浏览器的开发者面板,选择【元素】,切换到【计算样式】,之后勾选【全部显示】,此时你就能看到在此 h1 上面所有 CSS 属性对应的值。
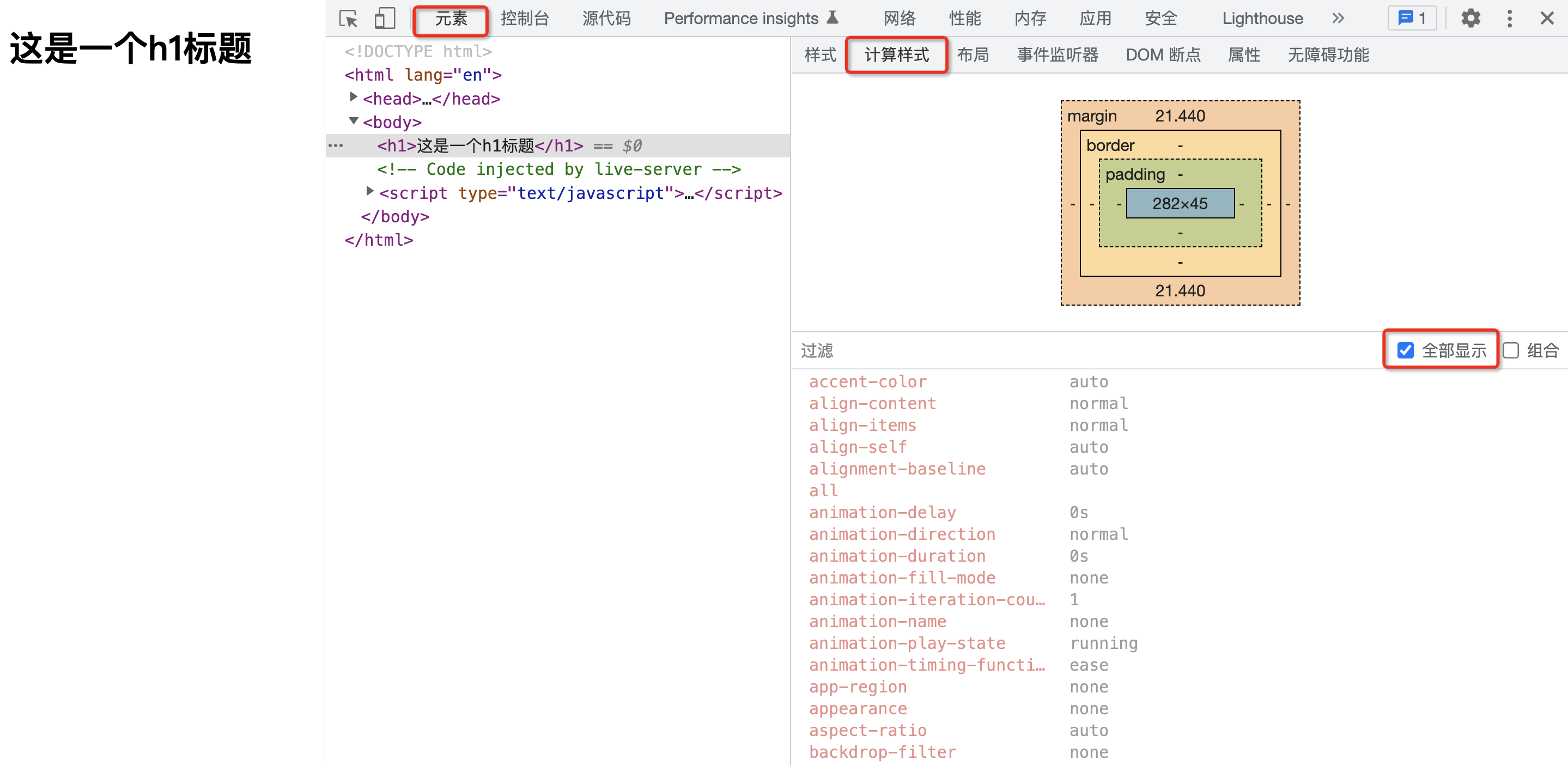
换句话说,我们所书写的任何一个 HTML 元素,实际上都有完整的一整套 CSS 样式。这一点往往是让初学者比较意外的,因为我们平时在书写 CSS 样式时,往往只会书写必要的部分,例如前面的:
1 | |
这往往会给我们造成一种错觉,认为该 p 元素上面就只有 color 属性。而真实的情况确是,任何一个 HTML 元素,都有一套完整的 CSS 样式,只不过你没有书写的样式,大概率可能会使用其默认值。例如上图中 h1 一个样式都没有设置,全部都用的默认值。
但是注意,我这里强调的是“大概率可能”,难道还有我们“没有设置值,但是不使用默认值”的情况么?
总的来讲,属性值的计算过程,分为如下这么 4 个步骤:
- 确定声明值
- 层叠冲突
- 使用继承
- 使用默认值
确定声明值
首先第一步,是确定声明值。所谓声明值就是作者自己所书写的 CSS 样式,例如前面的:
1 | |
当然,除了作者样式表,一般浏览器还会存在“用户代理样式表”,简单来讲就是浏览器内置了一套样式表。
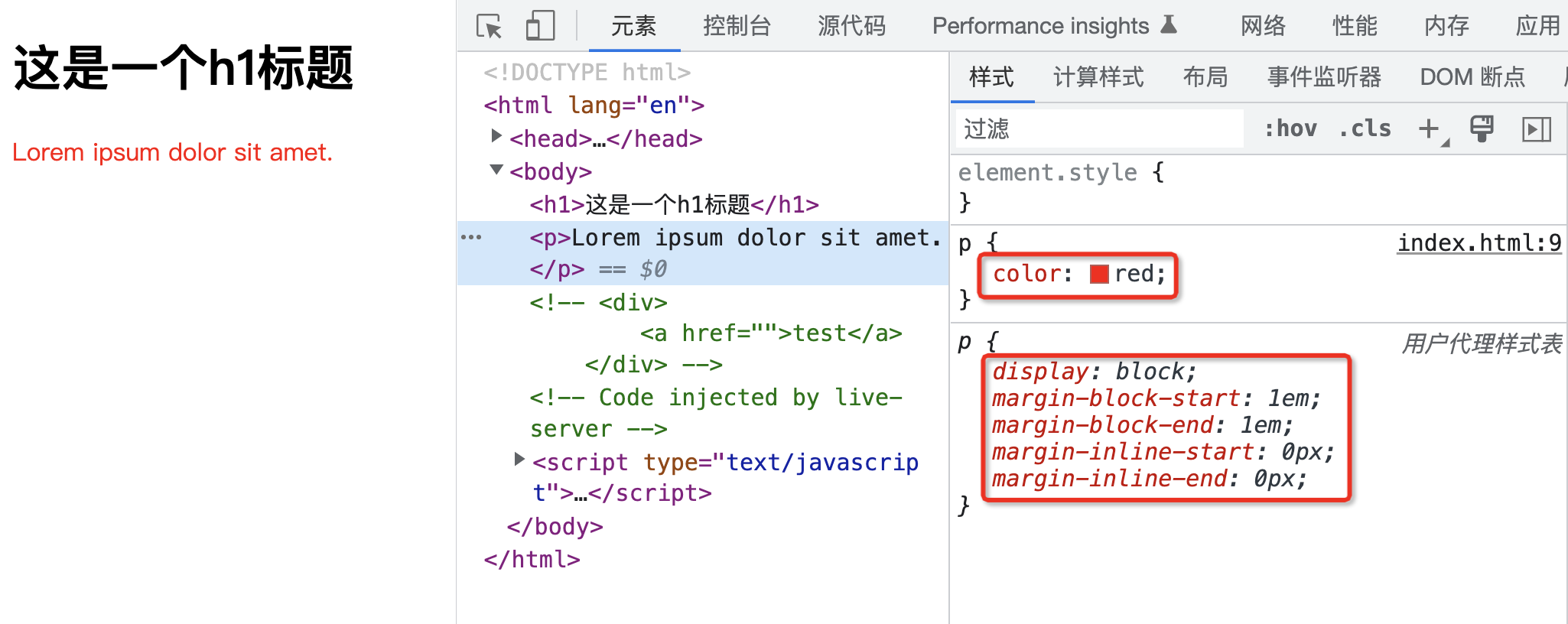
在上面的示例中,作者样式表中设置了 color 属性,而用户代理样式表(浏览器提供的样式表)中设置了诸如 display、margin-block-start、margin-block-end、margin-inline-start、margin-inline-end 等属性对应的值。
这些值目前来讲也没有什么冲突,因此最终就会应用这些属性值。
层叠冲突
在确定声明值时,可能出现一种情况,那就是声明的样式规则发生了冲突。
此时会进入解决层叠冲突的流程。而这一步又可以细分为下面这三个步骤:
- 比较源的重要性
- 比较优先级
- 比较次序
来来来,我们一步一步来看。
比较源的重要性
当不同的 CSS 样式来源拥有相同的声明时,此时就会根据样式表来源的重要性来确定应用哪一条样式规则。
那么问题来了,咱们的样式表的源究竟有几种呢?
整体来讲有三种来源:
- 浏览器会有一个基本的样式表来给任何网页设置默认样式。这些样式统称用户代理样式。
- 网页的作者可以定义文档的样式,这是最常见的样式表,称之为页面作者样式。
- 浏览器的用户,可以使用自定义样式表定制使用体验,称之为用户样式。
对应的重要性顺序依次为:页面作者样式 > 用户样式 > 用户代理样式
例如现在有页面作者样式表和用户代理样式表中存在属性的冲突,那么会以作者样式表优先。
1 | |
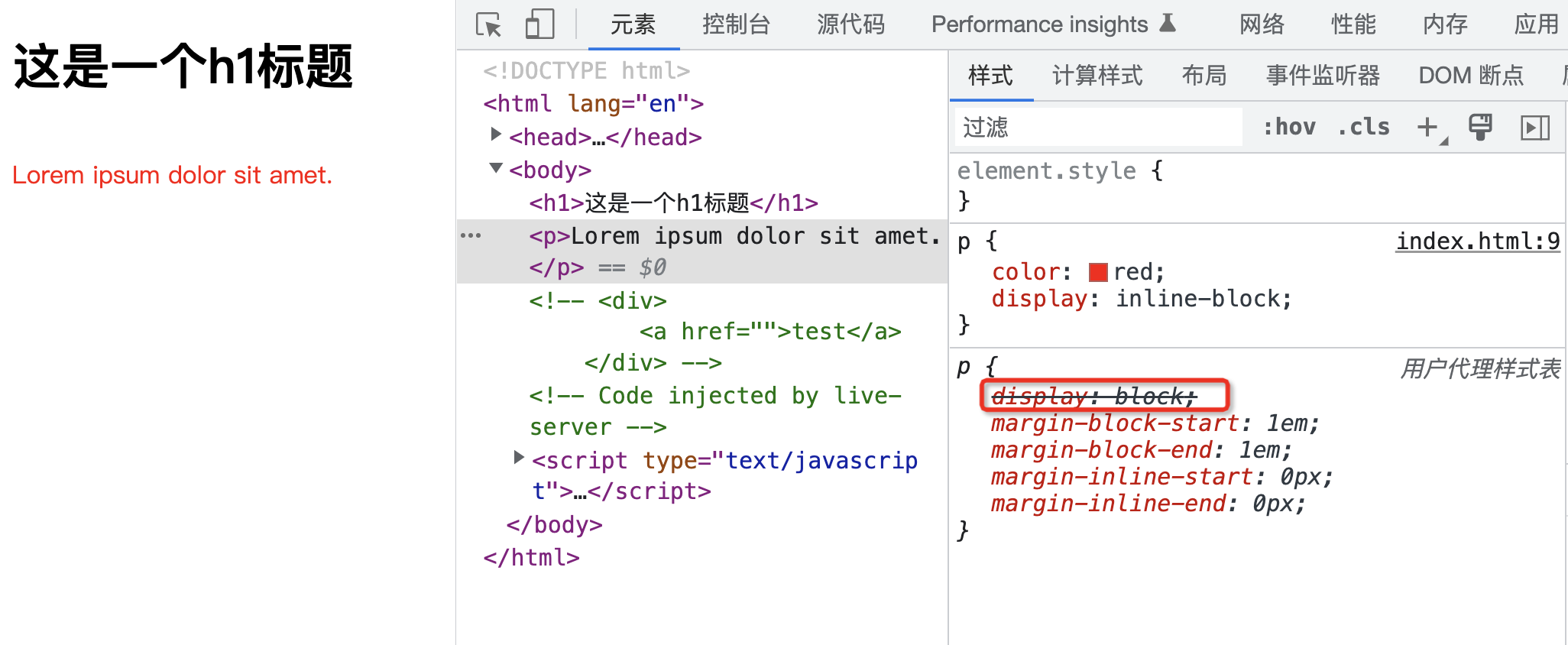
可以明显的看到,作者样式表和用户代理样式表中同时存在的 display 属性的设置,最终作者样式表干掉了用户代理样式表中冲突的属性。这就是第一步,根据不同源的重要性来决定应用哪一个源的样式。
比较优先级
那么接下来,如果是在在同一个源中有样式声明冲突怎么办呢?此时就会进行样式声明的优先级比较。
1 | |
1 | |
在上面的代码中,同属于页面作者样式,源的重要性是相同的,此时会以选择器的权重来比较重要性。
很明显,上面的选择器的权重要大于下面的选择器,因此最终标题呈现为 50px。
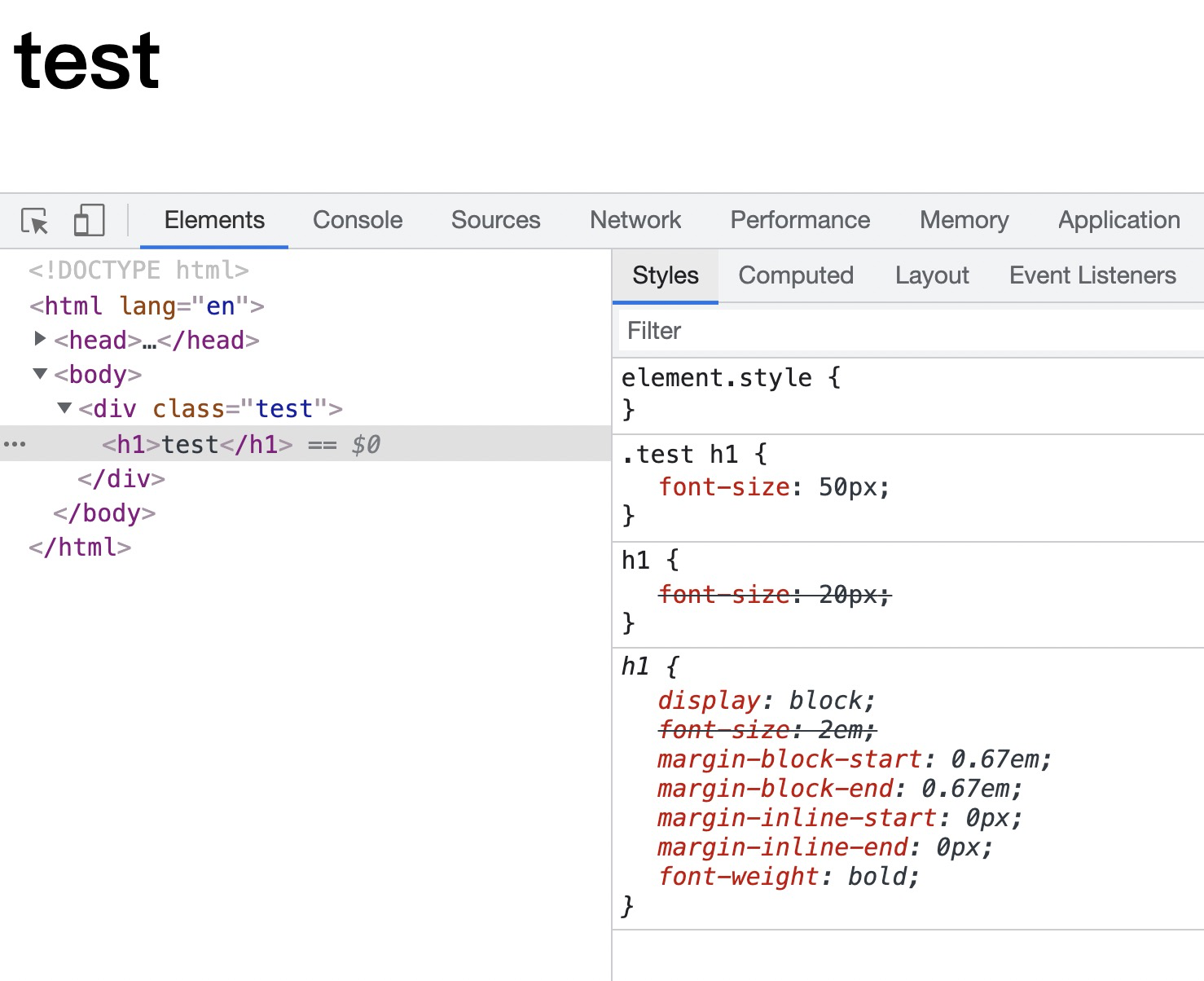
参考官网权重计算方法:https://developer.mozilla.org/zh-CN/docs/Web/CSS/Specificity
比较次序
经历了上面两个步骤,大多数的样式声明能够被确定下来。但是还剩下最后一种情况,那就是样式声明既是同源,权重也相同。
此时就会进入第三个步骤,比较样式声明的次序。
举个例子:
1 | |
在上面的代码中,同样都是页面作者样式,选择器的权重也相同,此时位于下面的样式声明会层叠掉上面的那一条样式声明,最终会应用 20px 这一条属性值。
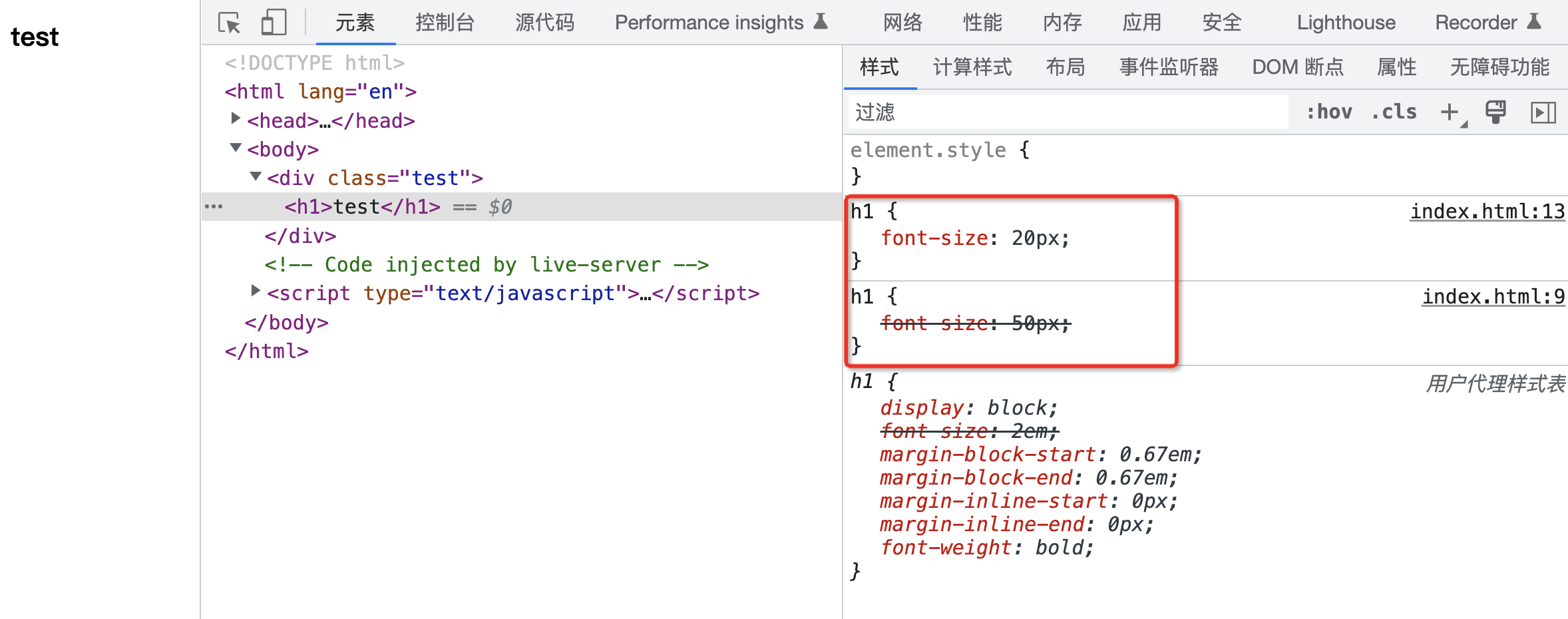
至此,样式声明中存在冲突的所有情况,就全部被解决了。
使用继承
层叠冲突这一步完成后,解决了相同元素被声明了多条样式规则究竟应用哪一条样式规则的问题。
那么如果没有声明的属性呢?此时就使用默认值么?
No、No、No,别急,此时还有第三个步骤,那就是使用继承而来的值。
例如:
1 | |
1 | |
在上面的代码中,我们针对 div 设置了 color 属性值为红色,而针对 p 元素我们没有声明任何的属性,但是由于 color 是可以继承的,因此 p 元素从最近的 div 身上继承到了 color 属性的值。
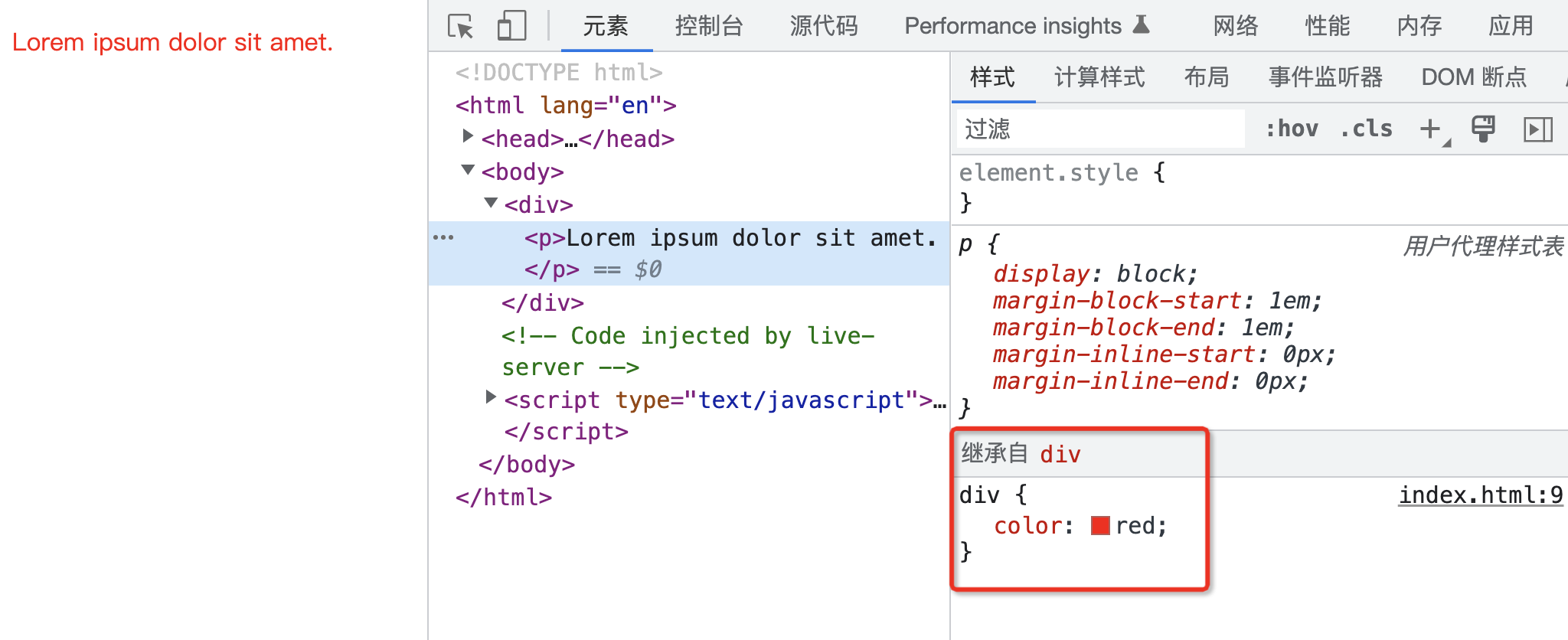
这里有两个点需要同学们注意一下。
首先第一个是我强调了是最近的 div 元素,看下面的例子:
1 | |
1 | |
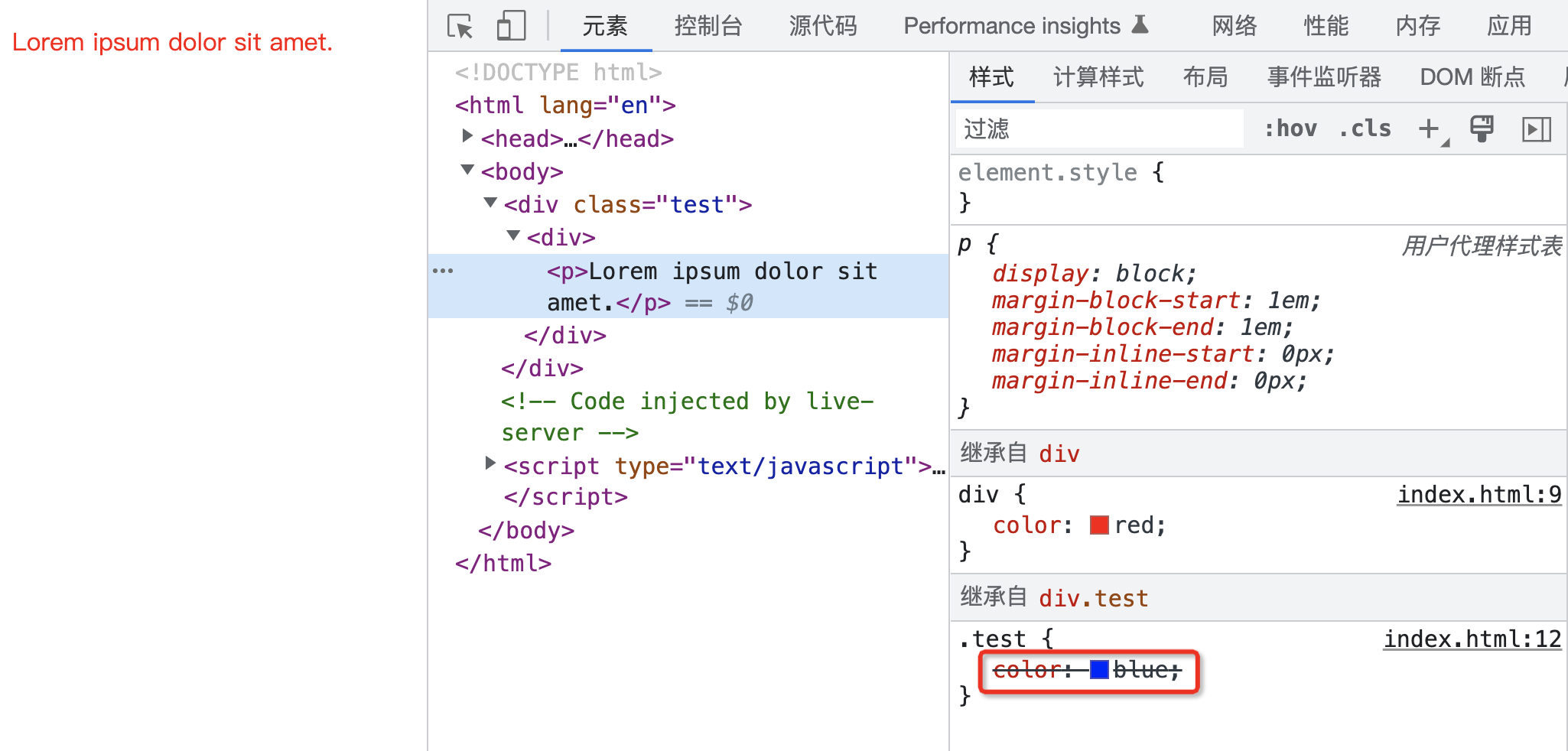
因为这里并不涉及到选中 p 元素声明 color 值,而是从父元素上面继承到 color 对应的值,因此这里是谁近就听谁的,初学者往往会产生混淆,又去比较权重,但是这里根本不会涉及到权重比较,因为压根儿就没有选中到 p 元素。
第二个就是哪些属性能够继承?
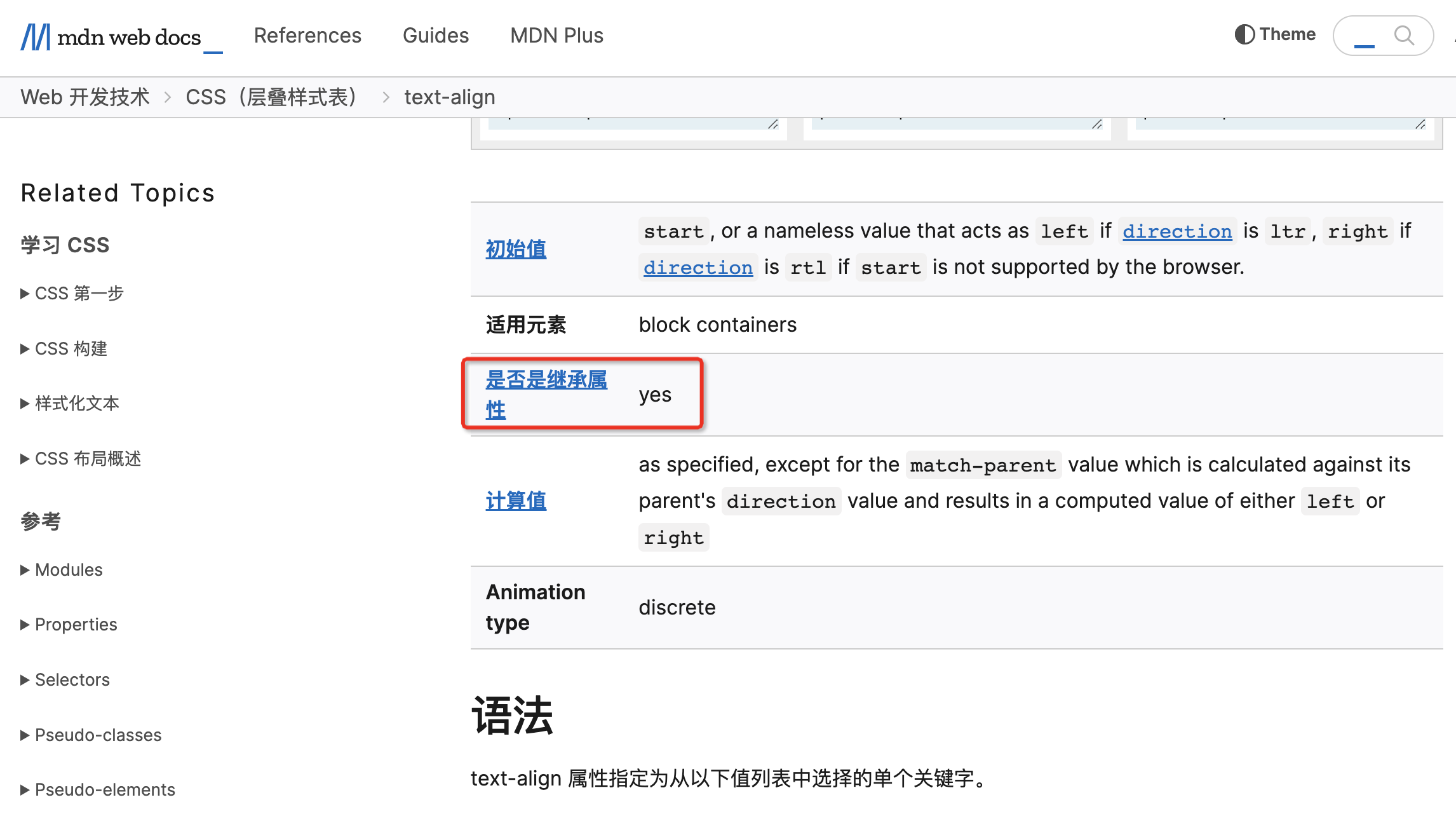
关于这一点的话,大家可以在 MDN 上面很轻松的查阅到。例如我们以 text-align 为例,如下图所示:
使用默认值
好了,目前走到这一步,如果属性值都还不能确定下来,那么就只能是使用默认值了。
如下图所示:
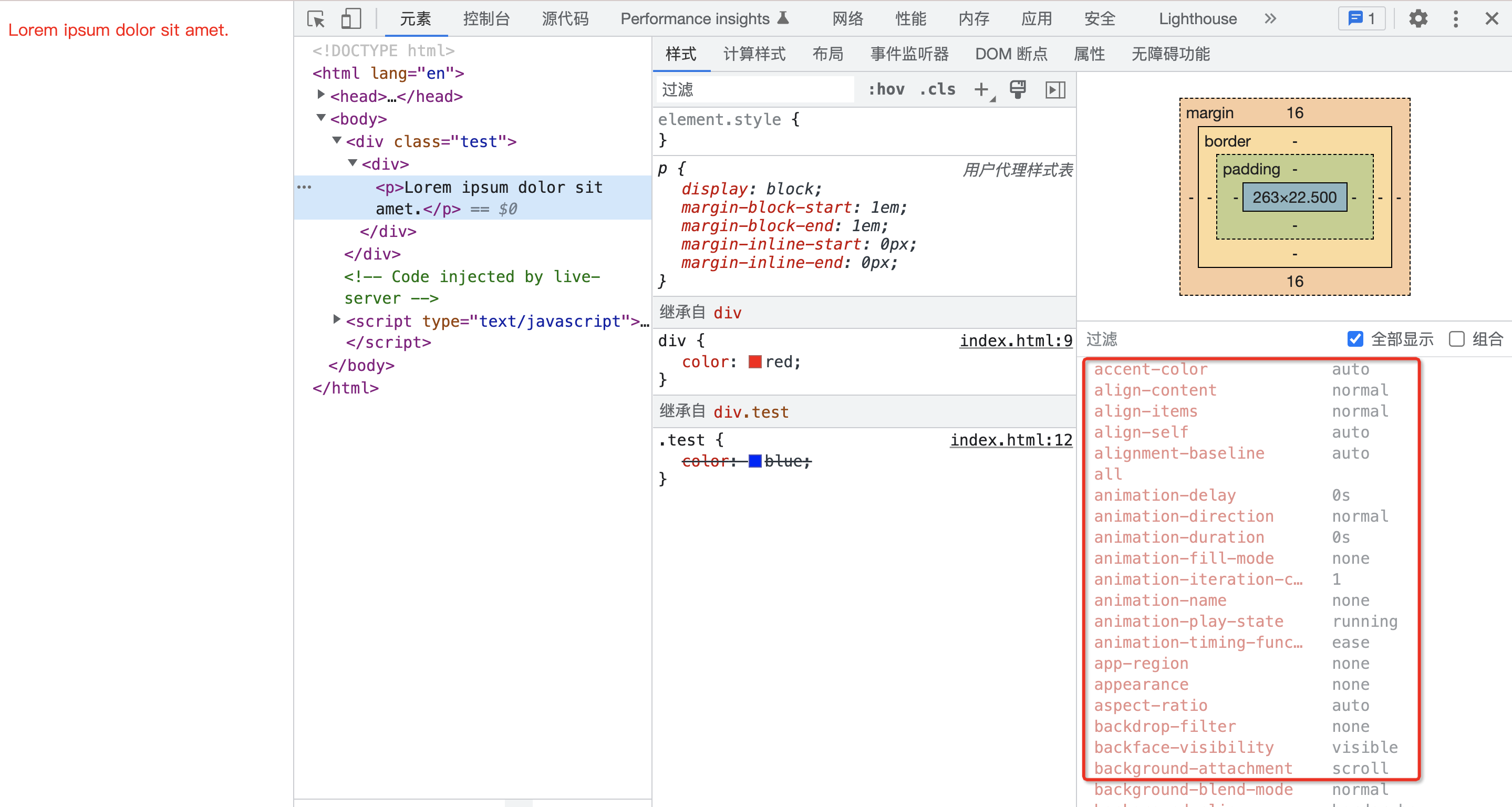
前面我们也说过,一个 HTML 元素要在浏览器中渲染出来,必须具备所有的 CSS 属性值,但是绝大部分我们是不会去设置的,用户代理样式表里面也不会去设置,也无法从继承拿到,因此最终都是用默认值。
面试题
下面的代码,最终渲染出来的效果,a 元素是什么颜色?p 元素又是什么颜色?
1 | |
1 | |
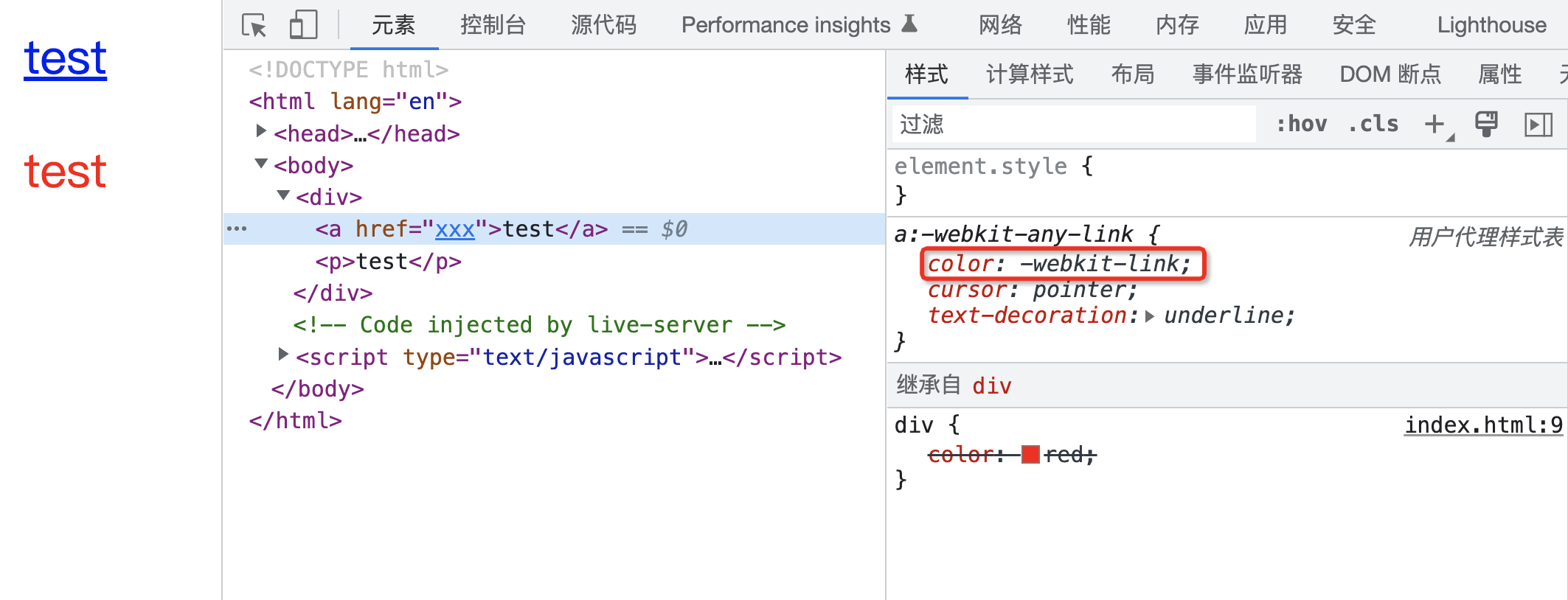
实际上原因很简单,因为 a 元素在用户代理样式表中已经设置了 color 属性对应的值,因此会应用此声明值。而在 p 元素中无论是作者样式表还是用户代理样式表,都没有对此属性进行声明,然而由于 color 属性是可以继承的,因此最终 p 元素的 color 属性值通过继承来自于父元素。
可以继承的元素

在CSS中,有一些属性可以被子元素继承,这意味着如果您在父元素上设置了这些属性,它们将被应用于其子元素,除非子元素明确地覆盖了这些属性。以下是一些常见的可继承属性:

- 字体属性:
font-familyfont-sizefont-weightfont-style
- 文本属性:
colorline-heighttext-aligntext-transformtext-indentletter-spacing
- 元素间距属性:
marginpadding
- 列表属性:
list-style
- 元素显示属性:
display
- 行高属性:
line-height
- 链接伪类属性:
a:linka:visited
- 其他属性:
cursor
需要注意的是,并不是所有的属性都可以继承。例如,background 和 border 属性通常不会被子元素继承。要了解特定属性是否可继承,可以查看该属性的文档或规范。此外,您也可以使用inherit关键字来明确指定一个属性的值应该继承自父元素,例如:
1 | |
这样,.child-element 元素的字体大小将与其父元素相同。
css包含块
一说到 CSS 盒模型,这是很多小伙伴耳熟能详的知识,甚至有的小伙伴还能说出 border-box 和 content-box 这两种盒模型的区别。
包含块英语全称为containing block,实际上平时你在书写 CSS 时,大多数情况下你是感受不到它的存在,因此你不知道这个知识点也是一件很正常的事情。但是这玩意儿是确确实实存在的,在 CSS 规范中也是明确书写了的:
https://drafts.csswg.org/css2/#containing-block-details

并且,如果你不了解它的运作机制,有时就会出现一些你认为的莫名其妙的现象。
那么,这个包含块究竟说了什么内容呢?
说起来也简单,就是元素的尺寸和位置,会受它的包含块所影响。对于一些属性,例如 width, height, padding, margin,绝对定位元素的偏移值(比如 position 被设置为 absolute 或 fixed),当我们对其赋予百分比值时,这些值的计算值,就是通过元素的包含块计算得来。
看下面例子:
1 | |
1 | |
请仔细阅读上面的代码,然后你认为 div.item 这个盒子的宽高是多少?

相信你能够很自信的回答这个简单的问题,div.item 盒子的 width 为 250px,height 为 150px。
这个答案确实是没有问题的,但是如果我追问你是怎么得到这个答案的,我猜不了解包含块的你大概率会说,因为它的父元素 div.container 的 width 为 500px,50% 就是 250px,height 为 300px,因此 50% 就是 150px。
这个答案实际上是不准确的。正确的答案应该是,div.item 的宽高是根据它的包含块来计算的,而这里包含块的大小,正是这个元素最近的祖先块元素的内容区。
因此正如我前面所说,很多时候你都感受不到包含块的存在。
包含块分为两种,一种是根元素(HTML 元素)所在的包含块,被称之为初始包含块(initial containing block)。对于浏览器而言,初始包含块的的大小等于视口 viewport 的大小,基点在画布的原点(视口左上角)。它是作为元素绝对定位和固定定位的参照物。
另外一种是对于非根元素,对于非根元素的包含块判定就有几种不同的情况了。大致可以分为如下几种:
- 如果元素的 positiion 是 relative 或 static ,那么包含块由离它最近的块容器(block container)的内容区域(content area)的边缘建立。
- 如果 position 属性是 fixed,那么包含块由视口建立。
- 如果元素使用了 absolute 定位,则包含块由它的最近的 position 的值不是 static (也就是值为fixed、absolute、relative 或 sticky)的祖先元素的内边距区的边缘组成。
前面两条实际上都还比较好理解,第三条往往是初学者容易比较忽视的,我们来看一个示例:
1 | |
1 | |
首先阅读上面的代码,然后你能在脑海里面想出其大致的样子么?或者用笔和纸画一下也行。
公布正确答案:
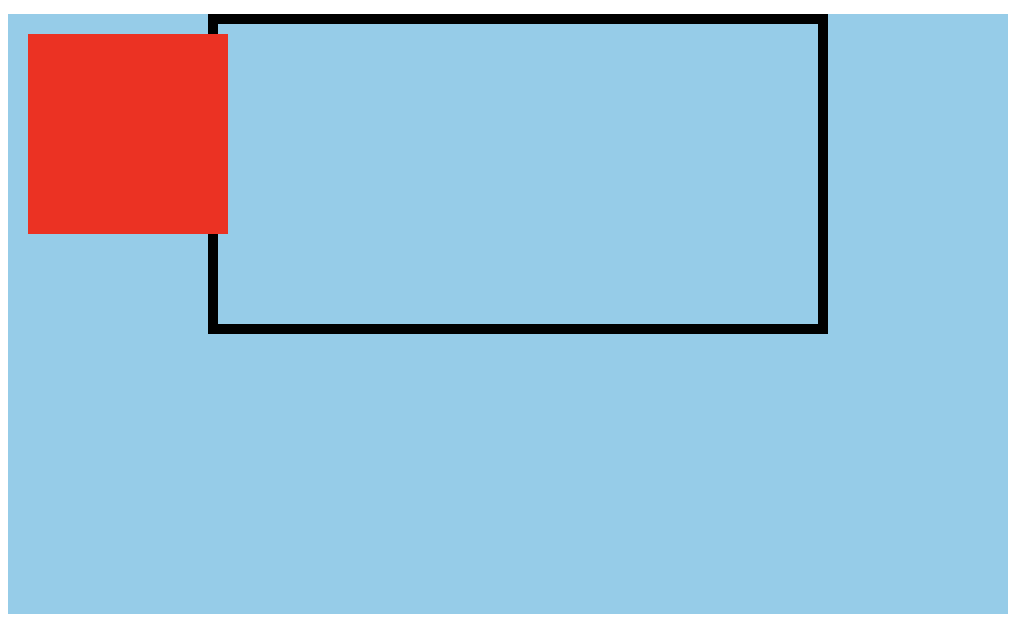
怎么样?有没有和你所想象的对上?
其实原因也非常简单,根据上面的第三条规则,对于 div.item2 来讲,它的包含块应该是 div.container,而非 div.item。
如果你能把上面非根元素的包含块判定规则掌握,那么关于包含块的知识你就已经掌握 80% 了。
实际上对于非根元素来讲,包含块还有一种可能,那就是如果 position 属性是 absolute 或 fixed,包含块也可能是由满足以下条件的最近父级元素的内边距区的边缘组成的:
- transform 或 perspective 的值不是 none
- will-change 的值是 transform 或 perspective
- filter 的值不是 none 或 will-change 的值是 filter(只在 Firefox 下生效).
- contain 的值是 paint (例如: contain: paint;)
我们还是来看一个示例:
1 | |
1 | |
我们对于上面的代码只新增了一条声明,那就是 transform:rotate(0deg),此时的渲染效果却发生了改变,如下图所示:

可以看到,此时对于 div.item2 来讲,包含块就变成了 div.item。
1 | |
上面是一段简单的 HTML 代码,在没有添加任何 CSS 代码的情况下,你能说出各自的包含块么?
| 元素 | 包含块 |
|---|---|
| html | initial C.B. (UA-dependent) |
| body | html |
| div1 | body |
| p1 | div1 |
| p2 | div1 |
| em1 | p2 |
| strong1 | p2 |
首先 HTML 作为根元素,对应的包含块就是前面我们所说的初始包含块,而对于 body 而言,这是一个 static 定位的元素,因此该元素的包含块参照第一条为 html,以此类推 div1、p1、p2 以及 em1 的包含块也都是它们的父元素。
不过 strong1 比较例外,它的包含块确实 p2,而非 em1。为什么会这样?建议你再把非根元素的第一条规则读一下:
- 如果元素的 positiion 是 relative 或 static ,那么包含块由离它最近的块容器(block container)的内容区域(content area)的边缘建立。
没错,因为 em1 不是块容器,而包含块是离它最近的块容器的内容区域,所以是 p2。
接下来添加如下的 CSS:
1 | |
上面的代码我们对 div1 进行了定位,那么此时的包含块会发生变化么?你可以先在自己思考一下。
| 元素 | 包含块 |
|---|---|
| html | initial C.B. (UA-dependent) |
| body | html |
| div1 | initial C.B. (UA-dependent) |
| p1 | div1 |
| p2 | div1 |
| em1 | p2 |
| strong1 | p2 |
可以看到,这里 div1 的包含块就发生了变化,变为了初始包含块。这里你可以参考前文中的这两句话:
- 初始包含块(initial containing block)。对于浏览器而言,初始包含块的的大小等于视口 viewport 的大小,基点在画布的原点(视口左上角)。它是作为元素绝对定位和固定定位的参照物。
- 如果元素使用了 absolute 定位,则包含块由它的最近的 position 的值不是 static (也就是值为fixed、absolute、relative 或 sticky)的祖先元素的内边距区的边缘组成。
是不是一下子就理解了。没错,因为我们对 div1 进行了定位,因此它会应用非根元素包含块计算规则的第三条规则,寻找离它最近的 position 的值不是 static 的祖先元素,不过显然 body 的定位方式为 static,因此 div1 的包含块最终就变成了初始包含块。
接下来我们继续修改我们的 CSS:
1 | |
这里我们对 em1 同样进行了 absolute 绝对定位,你想一想会有什么样的变化?
没错,聪明的你大概应该知道,em1 的包含块不再是 p2,而变成了 div1,而 strong1 的包含块也不再是 p2 了,而是变成了 em1。
| 元素 | 包含块 |
|---|---|
| html | initial C.B. (UA-dependent) |
| body | html |
| div1 | initial C.B. (UA-dependent) |
| p1 | div1 |
| p2 | div1 |
| em1 | div1(因为定位了,参阅非根元素包含块确定规则的第三条) |
| strong1 | em1(因为 em1 变为了块容器,参阅非根元素包含块确定规则的第一条) |
歌词滚动字幕实战
css/index.css
1 | |
js/data.js
1 | |
js/index.js
1 | |
index.html
1 | |
js使用文档片段的好处
在JavaScript中使用文档片段(Document Fragments)有多种好处,这些好处使得它们成为处理DOM操作时的有用工具之一:
- 性能提升:向DOM添加或删除元素会触发浏览器的重排和重绘,这可能会导致性能问题。使用文档片段可以减少这种问题,因为您可以在文档片段中进行所有的DOM操作,然后一次性将文档片段添加到DOM中。这减少了浏览器的操作次数,提高了性能。
- 更少的内存占用:文档片段存在于内存中,但它们不会像常规的DOM元素一样参与重排和重绘。这意味着文档片段在内存中的占用较小,因为它们不会触发布局计算。
- 代码整洁性:将相关的DOM操作封装在文档片段中可以使您的代码更整洁和可维护。这有助于将逻辑组织成更小、更易于理解的块。
- 减少浏览器渲染闪烁:如果您需要多次更新DOM,而没有使用文档片段,用户可能会看到多次闪烁或不稳定的渲染。使用文档片段可以减少这种不稳定性。
以下是一个使用文档片段的示例:
1 | |
在JavaScript中使用文档片段(Document Fragments)有多种好处,这些好处使得它们成为处理DOM操作时的有用工具之一:
- 性能提升:向DOM添加或删除元素会触发浏览器的重排和重绘,这可能会导致性能问题。使用文档片段可以减少这种问题,因为您可以在文档片段中进行所有的DOM操作,然后一次性将文档片段添加到DOM中。这减少了浏览器的操作次数,提高了性能。
- 更少的内存占用:文档片段存在于内存中,但它们不会像常规的DOM元素一样参与重排和重绘。这意味着文档片段在内存中的占用较小,因为它们不会触发布局计算。
- 代码整洁性:将相关的DOM操作封装在文档片段中可以使您的代码更整洁和可维护。这有助于将逻辑组织成更小、更易于理解的块。
- 减少浏览器渲染闪烁:如果您需要多次更新DOM,而没有使用文档片段,用户可能会看到多次闪烁或不稳定的渲染。使用文档片段可以减少这种不稳定性。
以下是一个使用文档片段的示例:
1 | |
在这个示例中,所有DOM操作都在文档片段中进行,然后一次性将文档片段添加到容器中,这样可以提高性能并减少浏览器重排和重绘的次数。
属性描述符
Object.defineProperty
JavaScript 属性描述符(Property Descriptors)是用于描述对象属性特性的对象。每个对象属性都有一个属性描述符,它定义了该属性的行为和特性。属性描述符包括以下属性:
- configurable(可配置性):表示是否可以通过
delete操作符删除属性并改变属性描述符。如果设置为false,则不能删除属性或修改其描述符(除非当前值为true)。 - enumerable(可枚举性):表示是否可以通过
for...in循环或Object.keys()方法枚举属性。如果设置为false,则该属性不会出现在枚举中。 - value(值):表示属性的值。可以是任何有效的 JavaScript 值。
- writable(可写性):表示属性是否可以被赋值修改。如果设置为
false,则属性值将保持不变,不允许重新赋值。 - get:一个函数,当访问属性值时调用。用于定义属性的 getter 方法。
- set:一个函数,当修改属性值时调用。用于定义属性的 setter 方法。
1 | |
1 | |
1 | |
Object.freeze和seal
在 JavaScript 中,Object.freeze() 和 Object.seal() 是两种用于限制对象属性和行为的方法,它们有不同的作用:
**
Object.freeze()**:Object.freeze()方法用于冻结一个对象,使其不可更改。一旦对象被冻结,就不能添加、删除或修改其属性,也不能修改对象的原型链。- 冻结后的对象属性的
writable特性会被设置为false,并且configurable特性也会被设置为false。这意味着不能修改属性值,也不能删除属性,也不能重新配置属性的描述符。 - 冻结对象后,无法再解冻它。这是一个深度冻结,也就是说,如果对象的属性是对象,那么这些属性的属性也会被冻结。
示例:
1
2
3
4
5
6
7
8
9
10
11javascriptCopy codeconst obj = {
prop1: 42,
prop2: 'Hello'
};
Object.freeze(obj);
obj.prop1 = 100; // 这个赋值操作不会生效
delete obj.prop2; // 这个删除操作也不会生效
console.log(obj); // 输出:{ prop1: 42, prop2: 'Hello' }**
Object.seal()**:Object.seal()方法用于封闭一个对象,使其属性不能添加或删除,但仍然可以修改属性值。- 封闭后的对象属性的
configurable特性会被设置为false,但writable特性仍然可以是true,这意味着可以修改属性的值,但不能重新配置或删除属性。
示例:
1
2
3
4
5
6
7
8
9
10
11javascriptCopy codeconst obj = {
prop1: 42,
prop2: 'Hello'
};
Object.seal(obj);
obj.prop1 = 100; // 这个赋值操作会生效
delete obj.prop2; // 这个删除操作不会生效
console.log(obj); // 输出:{ prop1: 100, prop2: 'Hello' }
总结:
Object.freeze()冻结对象,使其属性不能被修改、添加或删除。Object.seal()封闭对象,使其属性不能被添加或删除,但属性值可以被修改。- 这两个方法都用于限制对象的可变性,但根据需求选择哪个方法取决于是否需要允许属性值的修改。如果需要完全禁止属性值的修改,可以使用
Object.freeze();如果允许属性值的修改但不允许添加或删除属性,可以使用Object.seal()。
在 JavaScript 中,一旦你使用
Object.freeze()冻结了一个对象,它是不可解冻的。冻结是一个一次性的操作,无法撤销。这是因为冻结操作会将对象的属性配置设为不可修改的状态,并且不提供任何内置方法来撤销这个状态。封闭(sealing)一个对象的操作是不可逆的,无法直接解封(unseal)。一旦使用
Object.seal()封闭了一个对象,其属性配置会被设为不可更改,无法再重新配置或删除属性。这是一种安全性措施,确保对象的属性不会在封闭后被不经意地修改或删除。